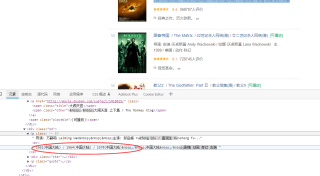
最近在学习爬虫,做“获取豆瓣网TOP250名单”这个案例的时候发现有两部电影的年份无法匹配导致无法获取,分别是
疯狂的麦克斯4:狂暴之路 2015年
黑客帝国 1999年
代码如下:
import re
import requests
url = "https://movie.douban.com/top250"
start = 0
myHeaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
while start < 250:
myParams = {
"start": start,
"filter": ""
}
resp = requests.get(url, headers=myHeaders, params=myParams)
getResult = re.finditer('<li>.*?<span class="title">(?P<filmName>.*?)</span>.*?'
'<br>.*?(?P<year>\d{4}) / (?P<region>.*?) .*?'
'<span class="rating_num".*?>(?P<score>.*?)</span>.*?'
'<span>(?P<remarkNum>.*?)人评价.*?</li>', resp.text, re.S)
for ele in getResult:
print(ele.groupdict())
start += 25
希望各位赐教,我这个年份匹配这里这么写为什么就只是匹配不到这两部电影的信息呢,其他248部都能获取