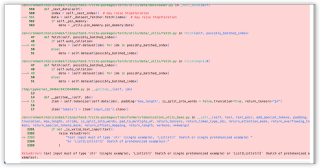
在运行roberta进行文本分类的时候,出现了下面的问题,该如何解决,请大家赐教:
class MLMDataset(torch.utils.data.Dataset):
def __init__(self, is_train, texts, tokenizer):
self.is_train = is_train
self.tokenizer = tokenizer
if self.is_train:
self.data = texts
else:
self.data = texts
### only use portion of data
length = int(len(self.data)/1)
self.data = self.data[:length]
###
def __getitem__(self, idx):
item = self.tokenizer(self.data[idx], padding='max_length', is_split_into_words = False,truncation=True, return_tensors="pt")
item['labels'] = item['input_ids'].clone()
probability_matrix = torch.full(item['labels'].shape, 0.15)
special_tokens_mask = [self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in item['labels'].tolist()]
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
item['labels'][~masked_indices] = -100
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
indices_replaced = torch.bernoulli(torch.full(item['labels'].shape, 0.8)).bool() & masked_indices
item['input_ids'][indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
# 10% of the time, we replace masked input tokens with random word
indices_random = torch.bernoulli(torch.full(item['labels'].shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(self.tokenizer), item['labels'].shape, dtype=torch.long)
item['input_ids'][indices_random] = random_words[indices_random]
# The rest of the time (10% of the time) we keep the masked input tokens unchanged
item['input_ids'] = item['input_ids'][0]
item['attention_mask'] = item['attention_mask'][0]
item['labels'] = item['labels'][0]
return item
def __len__(self):
return len(self.data)
datagram
运行结果及报错内容
ValueError: text input must of type str (single example), List[str] (batch or single pretokenized example) or List[List[str]] (batch of pretokenized examples).