
对于两个有关系的数据库表的查询(比如a表里属性包含b表的id,比如商品信息表和商品类型表),在前端显示商品列表时因为要显示类型的name,所以需要对这两个表进行联合查询,目前有两种方案:
一是:在SQL查询层面控制,在sql语句里对两个数据库表使用连接查询一次(join),比如

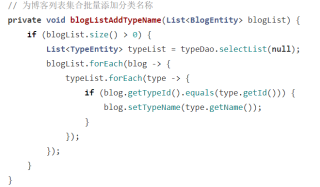
二是:在业务里分两次查询单个表的信息后,再遍历组合数据,比如
这两种方式,那种比较主流,性能比较好啊?或者有没有其他好的解决方案?

对于两个有关系的数据库表的查询(比如a表里属性包含b表的id,比如商品信息表和商品类型表),在前端显示商品列表时因为要显示类型的name,所以需要对这两个表进行联合查询,目前有两种方案:
一是:在SQL查询层面控制,在sql语句里对两个数据库表使用连接查询一次(join),比如
二是:在业务里分两次查询单个表的信息后,再遍历组合数据,比如
 分享
分享
 关注
关注你知道分两次查询再组合时,发生了一些什么吗?
应用把sql通过网络发到数据库,数据库解析sql,把整个表的数据从数据库的磁盘读出来到数据库的内存,然后通过网络把整个表传输到应用端的内存,两个表都是这样,然后在应用内存里排序再进行组合。而且这些动作还必须在每一次查询时发生,因为表里面的数据会变!当数据量一大,无论是磁盘读写、网络带宽、内存占用都是爆炸式上升,你应用速度能快才怪。为了查这么一条数据,你把几百万乃至上千万的数据搬过来搬过去,是为了啥?
反观在数据库里把最终需要的数据获取出来,通过网络传输的就只有你要的那一条记录,大大节省了各环节的开销
分享 系统已结题
1月28日
系统已结题
1月28日 已采纳回答
1月20日
创建了问题
1月20日
已采纳回答
1月20日
创建了问题
1月20日


