大家能帮忙看一下这个tf.nn.sparse_softmax_cross_entropy_with_logits的输入都是几维的么?为什么看注释的话好像预测值和标签值维度是不一样的阿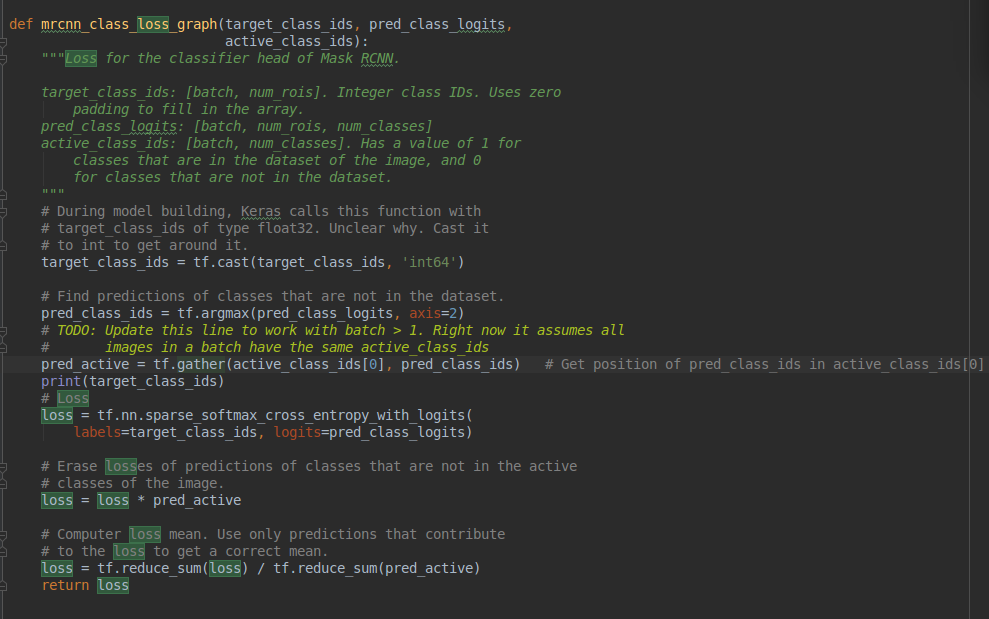

大家能帮忙看一下这个tf.nn.sparse_softmax_cross_entropy_with_logits的输入都是几维的么?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

 关注不知道你这个问题是否已经解决, 如果还没有解决的话:
关注不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇文章:坑爹啊,tf.nn.softmax_cross_entropy_with_logits坑了我好久 也许有你想要的答案,你可以看看
- 你还可以看下tensorflow参考手册中的 tf.nn.sparse_softmax_cross_entropy_with_logits
- 除此之外, 这篇博客: tf.nn.softmax_cross_entropy_with_logits 和 tf.contrib.legacy_seq2seq.sequence_loss_by_example 的联系与区别中的 1.2 tf.nn.sparse_softmax_cross_entropy_with_logits 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
主要区别:与上边函数不同,输入 labels 不是 one-hot 格式所以会少一维
函数输入:logits: [batch_size, num_classes]
labels: [batch_size]
logits和 labels 拥有相同的shape代码示例:
import tensorflow as tf labels = [0,1,2] #只需给类的编号,从 0 开始 logits = [[2,0.5,1], [0.1,1,3], [3.1,4,2]] logits_scaled = tf.nn.softmax(logits) result = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits) with tf.Session() as sess: print(sess.run(result))
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^解决 无用评论 打赏举报 分享
- 2021-09-15 11:21回答 1 已采纳 同学,你的indices搞反了 indices = np.vstack(( arr.row, arr.col)).transpose()
- 2021-05-03 17:32回答 1 已采纳 我把你的代码拿到本地跑了,首先你的代码的API是TF1.x版本的,我本地用的是tf1.15,所以第一步是把TF切换到1.15(我测试通过了,看你用Anaconda,那么安装就很简单了conda ins
- 2022-08-01 11:28回答 1 已采纳 这个一般是和显卡相关的一些东西,看名字应该是文件项目下面的用setup跑出来的文件会这么命名。你这个应该是个开源项目吧,仔细看下readme文件,里面一般会将怎么install项目并且运行demo,你
- 2020-07-22 23:56ManRock的博客 第一讲:神经网络的计算过程,搭建出你的第一个神经网络模型。 准备数据:采集大量“特征/标签”数据 搭建网络:搭建神经网络结构(前传) 优化参数:训练网络获取最佳参数(反传) 应用网络:将网络封装为模型,输入未曾...
- 2021-03-12 11:51回答 1 已采纳 【简单叙述】你装的是python3.9,我也是原来装的python3.9,在import pandas时,就没有用,都出现你这个问题。 【解决办法】卸载python3.9,装回python3.7,就不
- 2022-12-15 17:43回答 1 已采纳 你可以用一点小技巧,剔除掉有问题的图片,只读取OK的图片,中间部分修改后的代码如下,望采纳 for im in img_path: try: # 读取图
- 2021-04-25 11:33回答 1 已采纳 问题解决:直接在https://pytorch-geometric.com/whl/torch-1.6.0.html 下载好安装包,进行安装即可:
- 2018-07-28 19:04weixin_42001089的博客 本文首先介绍Skip-Gram模型,是基于tensorflow官方提供的一个demo,第二大部分是经过简单修改的CBOW模型,主要参考: https://www.cnblogs.com/pinard/p/7160330.html 两部分以####################...
- 2018-07-19 12:58回答 2 已采纳 请把xs, ys = mnist.train_step.next_batch(BATAH_SIZE)修改为xs, ys = mnist.train.next_batch(BATAH_SIZE),就可以
- 2019-10-30 17:03
 求解报错TypeError: slice indices must be integers or None or have an __index__ method
python
tensorflow
人工智能
机器学习
深度学习
回答 2 已采纳 y_pred = model.predict(X, diversity) 输出下x.shape diversity.shape 看下是多少 下标范围的问题
求解报错TypeError: slice indices must be integers or None or have an __index__ method
python
tensorflow
人工智能
机器学习
深度学习
回答 2 已采纳 y_pred = model.predict(X, diversity) 输出下x.shape diversity.shape 看下是多少 下标范围的问题 - 2020-07-28 10:50 modle.fit训练时出现InvalidArgumentError: logits and labels must have the same first dimension, got logits shape [20,40] and labels shape [800]
tensorflow
人工智能
深度学习
神经网络
回答 1 已采纳 https://blog.csdn.net/G_B_L/article/details/99871466
- 2019-07-15 14:00_我走路带风的博客 但是上面的输入是固定输入固定输出的,比如输入一张图片,输出一个类别,那么如果拿来做输入不固定,或者输出不固定,又或者二者都不固定的任务,是不是就没辙了,比如输入是一个句子,或者要求输出是一个句子,而且...
- 2023-03-30 17:39回答 2 已采纳 这个错误通常是由于在模型训练过程中发生了数据类型或形状不匹配的错误导致的。要解决这个问题,需要检查代码中的数据处理部分,以确保输入和输出的形状和数据类型与模型的期望相匹配。以下是一些可能导致此错误的常
- 2019-04-02 22:15我从崖边跌落的博客 Numpy: 1、numpy.random 链接 numpy中的random主要是用来产生随机数的一个模块。 2、numpy.newaxis链接 numpy中的newaxis主要是帮助数组创建新轴,或者也叫增加维度。...1、tf.argmax(a,axis=)/tf.red...
- 2022-05-29 20:01重邮研究森的博客 tensorflow0基础入门学习!!! 张量(Tensor) 概念:多维数组(列表)。其中阶数=张量的维数。...tf.int32 tf.float32 tf.float64 ...tf.constant([True,False])...创建一个Tensor 语法:tf.constant(张量内容,d..
- 2022-10-29 15:2599.99%的博客 全连接网络的作用就是对上一层得到的向量做乘法,最终降低其维度,然后输入到softmax层中得到对应的每个类别的得分。 在实际操作中,我们肯定是使用比average函数更复杂的聚合函数,也就是上面讲的那个传播函数。 ...
- 2023-03-21 19:23RozChan的博客 tf.int, tf.float…… tf.int 32, tf.float32, tf.float64 tf.bool tf.constant([True, False]) tf.string tf.constant(“Hello, world!”) 3.2 .如何创建一个张量 3.2.1 利用tf.constant tf.constant(张量内容,...
- 2020-03-13 20:53DOVIS_song的博客 1.tf.nn.bias_add(): 参考:https://blog.csdn.net/mieleizhi0522/article/details/80416668 一个叫bias的向量加到一个叫value的矩阵上,是向量与矩阵的每一行进行相加,得到的结果和value矩阵大小相同。 解释:...
- 2019-04-05 10:39菜鸟知识搬运工的博客 现在,每个图层都以 2D 表示,这使得神经元与其相应的输入进行匹配变得更加容易。 位于给定层的第 i 行第 j 列的神经元连接到位于前一层中的神经元的输出的第i行到第 行,第 j 列到第 列。 fh 和 fw 是...
- 2022-11-06 21:23Rachel MuZy的博客 LeNet5() # 编译网络(定义损失函数、优化器、评估指标) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 开始网络训练(定义训练数据与验证数据、定义训练代数,定义...
- 没有解决我的问题, 去提问
