关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
m0_61488091
2022-01-21 18:32
采纳率: 20%
浏览 58
首页
有问必答
已结题
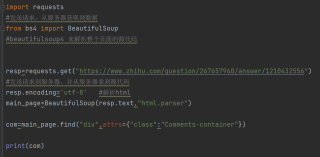
请问这个爬虫出了什么问题,他的结果是None
有问必答
python
爬虫
pycharm
这个出来的结果是None,想知道怎么回事,就是简单的爬取一个页面的评论
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
3
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
橙子园
领域专家: 大数据技术领域
2022-01-21 19:29
关注
你先把你的resp打印一下看看是否有你查找的标签,知乎的问题你可能直接爬不了
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
1
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(2条)
向“C知道”追问
报告相同问题?
提交
关注问题
分享
Python
7个
爬虫
小案例(附源码)
2022-10-22 07:00
艾派森的博客
本次的7个
python
爬虫
小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门
python
爬虫
的小伙伴参考学习。
python
爬虫
详解
2021-07-11 21:56
穆瑾轩的博客
python
爬虫
简介 ...和Google等,作为一个辅助人们检索信息的工具也存在着一定的局限性,通用搜索引擎的目标是尽可能大的网络覆盖率,返回的结果包含大量用户不关心的网页,为了解决上述
问题
,定..
python
爬虫
运行无结果_详解
Python
爬虫
爬取博客园
问题
列表所有的
问题
2021-02-04 06:27
蓝洱的博客
分析:首先博客园
问题
列表页面右键点击检查通过Element查找
问题
所对应的属性或标签可以发现在div class ="one_entity"中存在页面中分别对应每一个
问题
接着div class ="news_item"中h2标签下是我们...
python
爬虫
请求头是什么意思_
python
爬虫
请求头的使用
2021-01-14 07:23
PlutoAu的博客
这篇文章我们来讲一下在网站建设中,
python
爬虫
请求头的使用。本文对大家进行网站开发设计工作或者学习都有一定帮助,下面让我们进入正文。
爬虫
请求头网页获取:通过urlopen来进行获取requset.urlopen(url,data,time...
Python
万能代码模版:
爬虫
代码篇
2021-09-14 15:27
AI悦创Python一对一辅导的博客
但今天的
Python
课程是个例外,因为今天讲的 **
Python
技能,不需要你懂计算机原理,也不需要你理解复杂的编程模式。**即使是非开发人员,只要替换链接、文件,就可以轻松完成。 并且这些几个实用技巧,简直是 ...
python
爬虫
返回none_
Python
爬取网站,前几个有数据,之后返回None?
2020-12-23 11:21
weixin_39915721的博客
想获取廖雪峰
python
教程网站的内容练练手,发现有的章节能返回数据,但到
Python
基础这一章开始返回的都是None,没明白
问题
出
在哪,求教错误如下:Traceback (most recent call last):File "scraping_the_tutorial.py...
【
Python
爬虫
详解】第一篇:
Python
爬虫
入门指南
2025-04-20 09:15
Luck_ff0810的博客
为了应对不同的爬取需求和反爬挑战,
Python
生态系统提供了多种
爬虫
相关的库。库名特点适用场景Requests简单易用的HTTP库基础网页获取HTML/XML解析器静态网页内容提取Scrapy全功能
爬虫
框架大型
爬虫
项目Selenium浏览器...
Python
爬虫
实战实例:
Python
6个
爬虫
小案例(附源码)
2024-08-15 17:38
小尤笔记的博客
Python
所有方向路线就是把
Python
常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找...接下来将分享7个
Python
爬虫
的小案例,帮助大家更好地学习和了解
Python
爬虫
的基础知识。
python
爬虫
返回none_初学
python
爬虫
,bs4解析后print(bs,h1)返回None的原因和解决方案...
2021-01-14 12:42
weixin_39582569的博客
初学
爬虫
,结果第一个BeautifulSoup的实例就运行失败,print(bs,h1)返回None,但原网页明明就有h1标签。比如下面的代码。from bs4 import BeautifulSoupfrom urllib.request import urlopenhtml = urlopen('...
【
Python
网络
爬虫
】详解
python
爬虫
中URL资源抓取
2024-06-02 18:54
左手の明天的博客
要使用
Python
进行URL资源抓取,首先需要明确目标:是想要抓取网页的HTML内容,还是想要从网页中提取特定的数据(如文本、链接、图片等...以下是一个基本的步骤指南,以及相关的代码示例,帮助你开始URL资源抓取的工作。
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
1月29日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
1月21日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
1月21日


 分享
分享
 关注 分享
关注 分享 系统已结题
1月29日
系统已结题
1月29日 已采纳回答
1月21日
创建了问题
1月21日
已采纳回答
1月21日
创建了问题
1月21日

