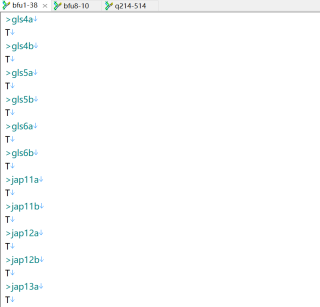
以下是代码,但是跑不出来结果,可能是字典的那一步value没写如成功,后面显示的空的DataFrame,但是现在不知道怎样去修改?
import os
import pandas as pd
files_dir = "C:/Users/lanlan/Desktop/filefas_join/"
data_dict = dict()
for file_name in os.listdir():
if os.path.splitext(file_name)[1].lower() in '.fas':
file_name_dir = os.path.join(files_dir, file_name)
with open(file_name_dir) as file_data:
data_dict[file_name] = {}
print(data_dict)
i = 0
for line in file_data:
line = line.strip('\n')
i = i + 1
if line.startswith('>'):
key = line
print(key)
list_need = []
data_dict[file_name][key] = list_need
df_all = pd.DataFrame({'key': [], 'value': []})
print(df_all)
for dict_name in data_dict:
key_ls = []
value_ls = []
dict_name_ls = dict_name.split('.')[0]
data = {'key': key_ls, dict_name_ls: value_ls}
df_A = pd.DataFrame.from_dict(data)
df_all = pd.merge(df_all, df_A, on='key', how='outer')
df_all = df_all.sort_values(by='key')
print(df_all)
df_all.to_excel(files_dir + 'snpstr.xlsx')
三个文件的格式是一样的,都是以下格式: