
我在做一个利用selenium模块,抓取淘宝数据的自动化程序。前面的自动打开浏览器,自动输入搜索内容,自动滑动网页游标都能够正常运行,但是到抓取淘宝数据时,却报错。给出的报错原因是找不到此元素。具体问题如下图:
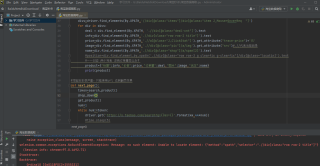

出错的代码是:info=div.find_element(By.XPATH,'.//div[class="row row-2 title"]').text
我知道内容在a标签里面,但是这里面不仅有span的内容,还有直接的文本内容。我试着在这段代码的class里面加了/a/text()[1]/span[2]/test()[2]/span[3],得到的结果同样是报错。后面我又修改了等待的时间,同样也是报错。、
大家看看这是哪里出了问题?该怎么解决?







