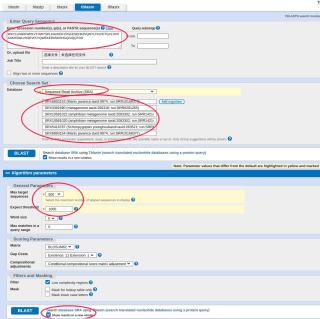
需要对一个搜索网站进行批量搜索,要求是shell脚本或者python脚本
搜索网站:https://blast.ncbi.nlm.nih.gov/Blast.cgi?PROGRAM=tblastn&PAGE_TYPE=BlastSearch&LINK_LOC=blasthome
网页搜索需要提交的参数是:
1, Enter Query Sequence搜索框内容:
WKYLLPARFWPKVTHWYSPLKAVKDKYPGFESEHKIIVQNYLTKLFETGVLYKRASKHSWLVHSEVPLYQWEKERIISKHHGQGIQQTDD
2,Database下拉框选择:Sequence Read Archive(SRA),同时在使用add organism加入搜索的一系列ID号码,这个ID号码在一个txt文件里面,每一行一个ID,可能有10000个ID要搜索——自动化批量搜索的关键所在。由于网站有限制,可以设置10分钟搜索一次,一次搜索10个ID。
3,搜索参数设置:
Max target sequences由默认100改成500
Expect threshold由默认0.05改成1000
Show results in a new window:勾选
4,ID-test.txt测试数据6个ID,一次搜索2个ID,分成3次搜索完成,每次间隔10分钟。
ID-test.txt
SRR8618023
SRR14214524
SRR14214522
SRR6291255
SRX6893153
SRX6893154
补充4,由于网站输入id时候会自动搜索转换id,为简化问题,直接使用网站转化后的id测试。6个ID,一次搜索2个ID,分成3次搜索完成,每次间隔10分钟。
test-id.txt
SRX5416787 (Schizopygopsis younghusbandi taxid:263521; run:SRR8618023)
SRX10581020 (amphibian metagenome taxid:2083302; run:SRR14214524)
SRX10581022 (amphibian metagenome taxid:2083302; run:SRR14214522)
SRX3392490 (metagenome taxid:256318; run:SRR6291255)
SRX6893153 (Manis javanica taxid:9974; run:SRR10168378)
SRX6893154 (Manis javanica taxid:9974; run:SRR10168377)
5,搜索结果:
点击搜索以后有一个Request ID比如YXJABRJT013,返回这个Request ID到Reslut.txt文件里面即可
6,100元在此仅仅是测试是否可以能够初步完成该网站的批量自动化搜索,至少脚本能初步完成ID-test.txt搜索测试。要求是shell脚本或者python脚本——我只能看得懂这两个语言,如果有更好更简单的办法也可以,只要我看得懂。