需求:
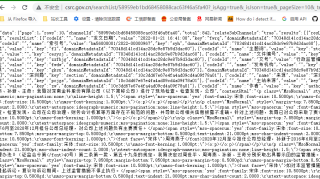
深圳证监会政府公开页面http://www.csrc.gov.cn/shenzhen/ ... gk.shtml?tab=zdgkml
爬取主动公开目录-证监局文种体裁-行政监管措施的842条数据制表
url的发掘:网页内信息变动网址不变,就从开发者工具里找到Request URL
第一页为http://www.csrc.gov.cn/searchLis ... nelName=&page=1
所以程序通过修改“page=”后面的数字实现翻页
但是遭遇了
Traceback (most recent call last):
File "D:\pythonProject\test 行政监管措施爬取.py", line 85, in
main()
File "D:\pythonProject\test 行政监管措施爬取.py", line 19, in main
saveData(datalist,savepath)
File "D:\pythonProject\test 行政监管措施爬取.py", line 77, in saveData
data = datalist
IndexError: list index out of range
不会修改,知识匮乏,请指导
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象
findTitle = re.compile(r'<a title="(.*?)">')
findNumber = re.compile(r'<td class="fwrq">(.*)</td>')
findDate = re.compile(r'<span class="date">(.*)</span>')
def main():
baseurl = "http://www.csrc.gov.cn/searchList/58959eb1bd68458088cac63f46a5fa40?_isAgg=true&_isJson=true&_pageSize=10&_template=index&_rangeTimeGte=&_channelName=&page=" #要爬取的网页链接
# 爬取网页
datalist = getData(baseurl)
savepath = "深圳证监会行政监管措施.xls" #当前目录新建XLS,存储进去
# 保存数据
saveData(datalist,savepath)
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 85): # 调用获取页面信息的函数,85次
url = baseurl + str(i)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串
data = [] # 保存一个文件的所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
title = re.findall(findTitle, item)[0]
data.append(title)
number = re.findall(findNumber, item)[0]
data.append(number)
date = re.findall(findDate, item)[0]
data.append(date)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
# 模拟浏览器头部信息,向sz证监会服务器发送消息
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 Edg/97.0.1072.69"
}
# 用户代理,表示告诉sz证监会服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('深圳证监会行政监管措施', cell_overwrite_ok=True) #创建工作表
col = ("行政监管措施链接","标题","文号","发文日期")
for i in range(0,4):
sheet.write(0,i,col) #列名
for i in range(0,842):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist
for j in range(0,4):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
print("爬取完毕!")