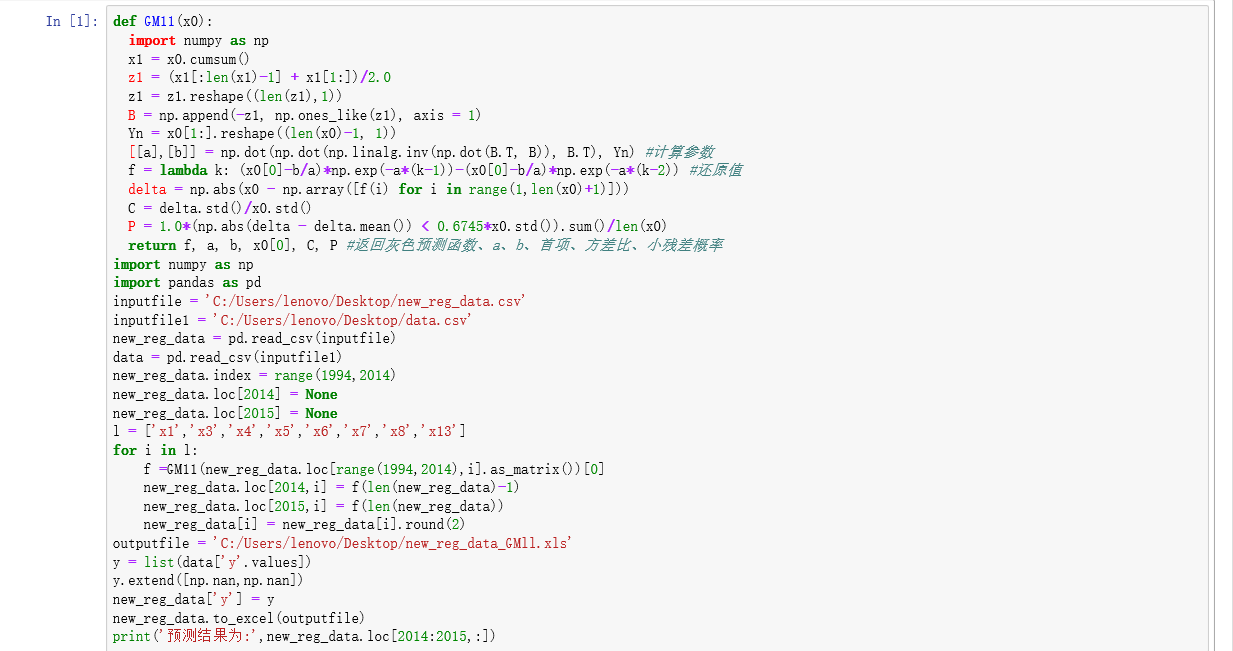
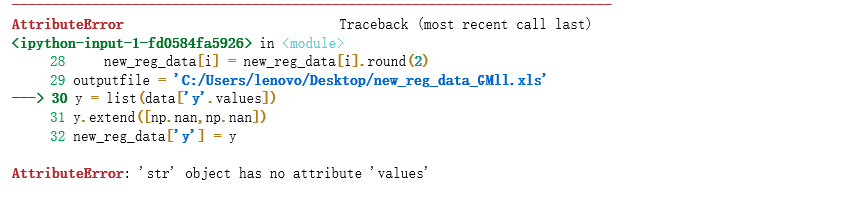

python出现问题:AttributeError: 'str' object has no attribute 'values'

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 云天徽上的博客 是一个常见的Python错误,它通常意味着你正在尝试在一个字符串上调用一个不存在的属性或方法。要解决这个问题,你需要检查你的代码,确保你正在访问的属性或方法名是正确的,并且该属性或方法确实存在于你操作的对象...
- 二川bro的博客 【python 已解决!】 AttributeError: 'str' object has no attribute 'example' 详解与解决方案
- 2022-08-02 23:22RaptorWE的博客 AttributeError: 'str' object has no attribute 'items' 译文:AttributeError: 'str'对象没有属性'items" 序列化器忘写 class Meta: 元类
- E绵绵的博客 通过本文,你不仅学到了如何解决 “AttributeError: ‘list’ object has no attribute ‘shape’” 的错误,还了解了如何使用工具和策略来预防未来可能的错误。正确地使用数据类型是Python编程中的一项基本技能,...
- 2024-04-22 21:01元气满满毅力坚定沉迷学习无法自拔的博客 项目场景: 相关背景:训练网络时,路径报错 目标(路径)没有后缀(.jpg/.png/tif等等) 原因分析: 路径加载方式问题 解决方案: 将os.join(path,fileName)的文件加载方式改为pathlib式: img=pathlib.Path(path)/...
- 2024-05-28 12:37AI小怪兽的博客 YOLOv10报错解决:AttributeError: 'str' object has no attribute 'view'
- 2021-04-08 09:55spring_cloudy的博客 《AttributeError: 'str' object has no attribute 'decode'》。这种问题我也不是很熟悉,他说要有关编码encode\decode等的问题。因为我也不懂,所以就记录一下怎么去修改问题,并没有实现他的本质。 问题出现来源...
- 2022-07-26 10:49Funing7的博客 AttributeError报错处理
- 2022-11-10 21:07小满大王i的博客 已解决(json.load()读取json文件报错)AttributeError: ‘str‘ object has no attribute ‘read
- 2021-03-05 14:05福将~白鹿的博客 错误:AttributeError: ‘str’ object has no attribute ‘items’ 错误很清晰,DictVectorizer,只能训练并转换dict类型数据,而真实数据却为str。 解决方案:str转换为dict 方法推荐:todict() 问题解决,其实...
- 高斯小哥的博客 【Python实战】轻松搞定`AttributeError: ‘Series’ object has no attribute ‘columns’`! 你是否曾遇到过处理Pandas数据时,`Series`对象却“假装”有`columns`属性的尴尬?♂️ 不用怕,这篇博客为你揭秘`...
- 2024-10-13 19:08默语佬的博客 在Python编程中,AttributeError: ‘str’ object has no attribute 'x’通常出现在试图访问字符串对象中不存在的属性时。本文将详细探讨该错误的成因、影响以及如何解决这一问题,结合代码示例帮助你快速掌握处理...
- 2022-03-01 15:36weixin_52472280的博客 AttributeError: 'str' object has no attribute 'open_url'
- 2020-01-13 22:38yeliang23的博客 报错:AttributeError: ‘function’ object has no attribute 解决:可能文件名和方法名重名了
- 没有解决我的问题, 去提问
