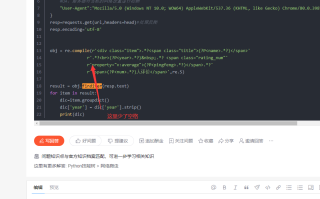
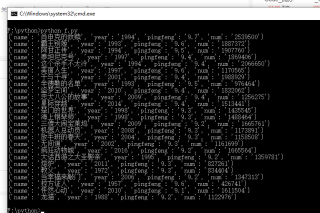
想要爬取出我要的数据
import requests
import re
url="https://movie.douban.com/top250"
head={
#UA,服务器对当前的网络设置进行检测
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0"
}
resp=requests.get(url,headers=head)#处理反爬
resp.encoding='utf-8'
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<br>(?P<year>.*?) .*? <span class="rating_num"'
r'property="v:average">(?P<pingfeng>.*?)</span>.*?'
r'<span>(?P<num>.*?)人评价</span>',re.S)
result = obj.finditer(resp.text)
for item in result:
dic=item.groupdict()
dic['year'] = dic['year'].strip()
print(dic)