1.问题
oracle 11g版本,一张用户参加活动的流水表,就参加某一活动的所有用户数目,进行去重统计。采用group by或distinct去重时,发现磁盘一直100%,速度过慢。
2.sql执行结果图
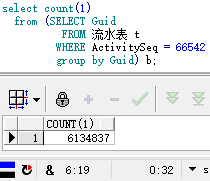
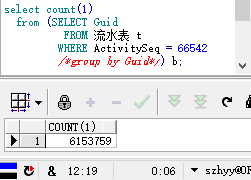
上图去重耗时=32s,下图不去重耗时=6s(相关字段均已建立索引,且索引未失效)。
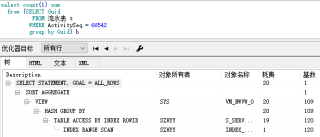
3.sql解析计划图
4.请问
我发现耗时出现在group by、count(1)统计,导致的大量磁盘读写上,这种sql查询要如何优化呢?
或者有什么别的设计方法,可以避开这种问题呢?

oracle 11g版本,一张用户参加活动的流水表,就参加某一活动的所有用户数目,进行去重统计。采用group by或distinct去重时,发现磁盘一直100%,速度过慢。
上图去重耗时=32s,下图不去重耗时=6s(相关字段均已建立索引,且索引未失效)。
我发现耗时出现在group by、count(1)统计,导致的大量磁盘读写上,这种sql查询要如何优化呢?
或者有什么别的设计方法,可以避开这种问题呢?
 分享
分享 这sql优化我搞不出来了,改成代码里选用redis的典型应用场景解决了😂
分享 系统已结题
2月18日
系统已结题
2月18日 已采纳回答
2月10日
创建了问题
2月8日
已采纳回答
2月10日
创建了问题
2月8日

