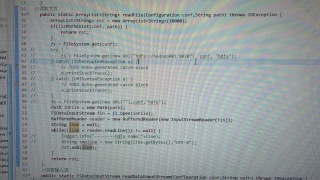
程序最初是jar包在单机执行的,执行过程中同样使用了hdfs上的文件 不过在执行jar包的时候指定了file.encoding=utf8所以未出现乱码问题
现在程序改成了mapreduce运行在集群上 在reduce端读取了hdfs上的文件 本想的是在reduce将数据量不多的数据读出做全局变量使用 与map端输出过来的数据做比对 结果reduce端读的数据乱码了 本想在运行mapreduce的时候指定编码 结果指定的编码都被当做jar包的入参解析了
文件都是utf8的 服务器的lang也改成utf8了 jar包也是utf8编译的 求大佬指点迷津
这个图是reduce端读文件做了基本处理后的输出
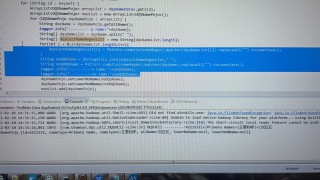
这个是输出的数据
这个是读hdfs的方法