HtmlUnit爬网页不完整,缺少一些标签该如何解决?
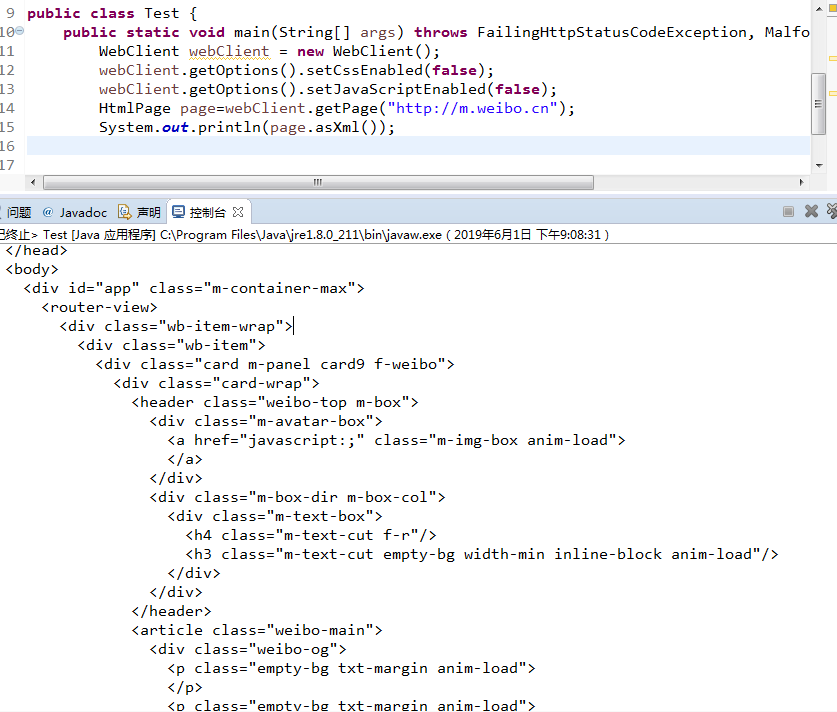
我用HtmlUnit中的WebClient.getPage()爬微博手机网页,但输出后发现比用浏览器查看的源码要少一部分标签,请教一下这是什么原因呢?有没有什么解决办法。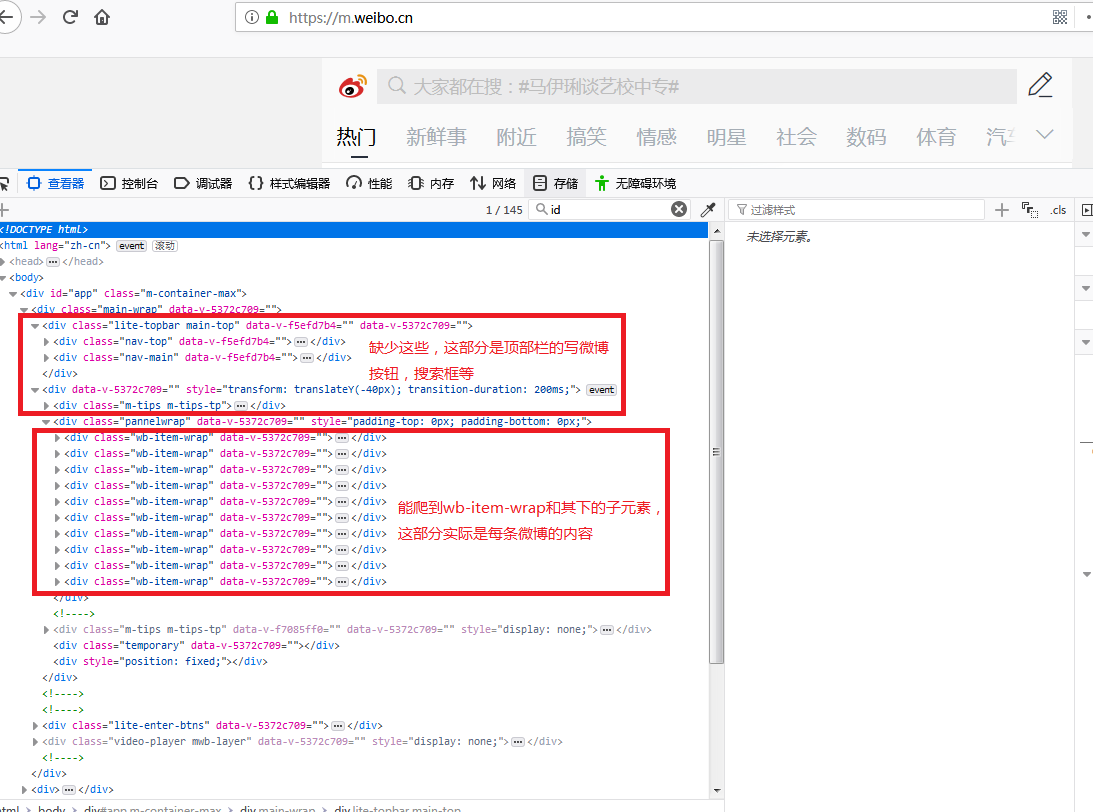

HtmlUnit爬网页不完整,缺少一些标签该如何解决?
我用HtmlUnit中的WebClient.getPage()爬微博手机网页,但输出后发现比用浏览器查看的源码要少一部分标签,请教一下这是什么原因呢?有没有什么解决办法。
 分享
分享
可能是因为HtmlUnit默认是不会执行JavaScript的,而一些网页的内容是通过JavaScript动态加载的,所以在使用WebClient.getPage()时可能会出现缺少标签的情况。解决方法是在获取页面之前,先设置WebClient的选项,让它支持JavaScript的执行。可以使用如下代码:
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(true);
HtmlPage page = webClient.getPage("http://www.example.com");
这样就可以获取完整的网页内容了。
分享

