问题遇到的现象和发生背景
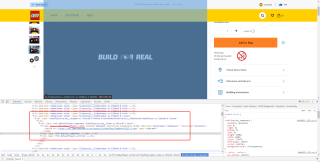
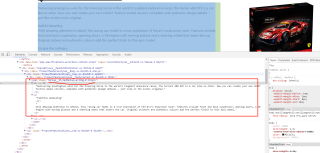
问题相关代码,请勿粘贴截图
import scrapy
class LegoSpider(scrapy.Spider):
name = 'lego'
allowed_domains = ['www.lego.com']
start_urls = ['https://www.lego.com/en-gb/product/ferrari-488-gte-af-corse-51-42125']
def parse(self, response):
#获取所有图片集合
images = response.css(".ThumbnailsTrackstyles__TrackContainer-sc-141n2vw-3.hSgYMJ img::attr(src)").getall()
#所有视频url链接
print(response.css(".rh5v-DefaultPlayer_video source::attr(src)").getall())
#商品详情
print(response.css(".Markup__StyledMarkup-ar1l9g-0.hlipzx p::text").getall())
return {"images":images}
运行结果及报错内容
运行之后返回的空集合
我的解答思路和尝试过的方法
我尝试用xpath获取结果以及css的方式获取都获取不到,不知道为什么