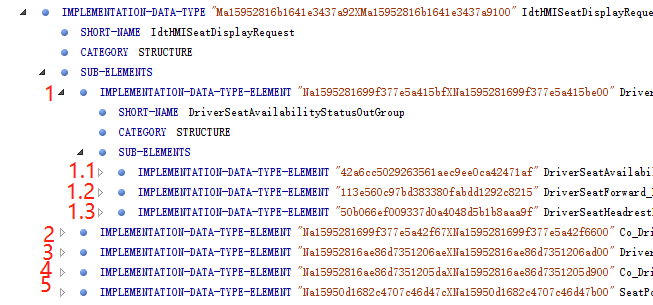
读取xml文件,
获取如下标签的NodeList,
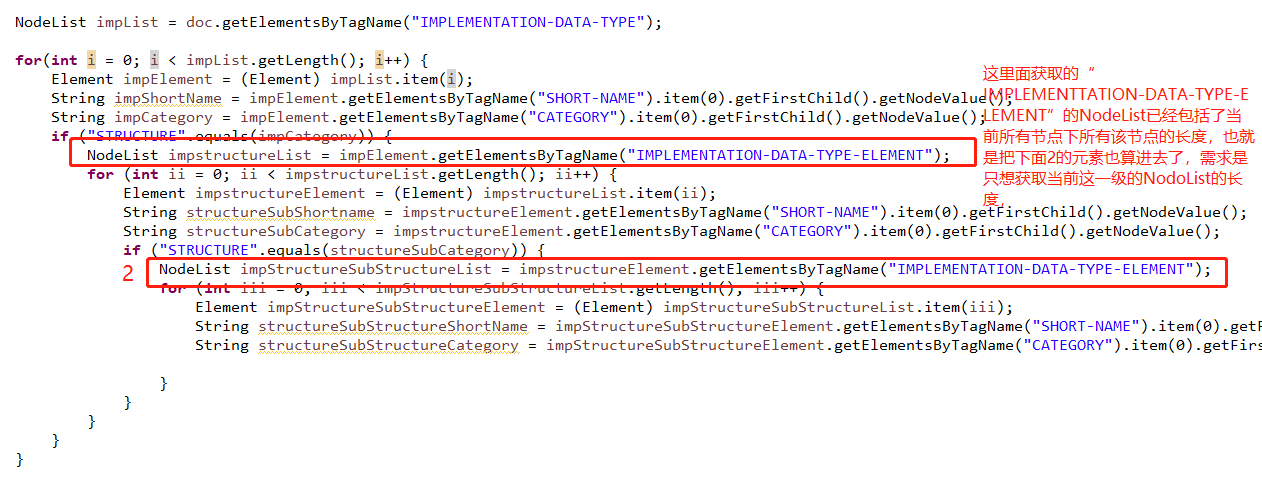
NodeList impList = doc.getElementsByTagName("IMPLEMENTATION-DATA-TYPE");
for(int i = 0; i < impList.getLength(); i++) {
Element impElement = (Element) impList.item(i);
NodeList impSubList = impElement.getElementsByTagName("IMPLEMENTATION-DATA-TYPE-ELEMENT");
System.out.println("impSubList legth= " + impSubList.getLength());
}
我想做到输出的impSubList legth=5,但是实际输出的长度是这个节点下所有的这个便签的长度。怎么一级一级解析下去 获取长度?