关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
心大自然宽
2022-02-23 15:27
采纳率: 72.7%
浏览 56
首页
Python
已结题
Jupyter Notebook 爬取网页内容时出来的结果是乱码要怎么解决
python
jupyter
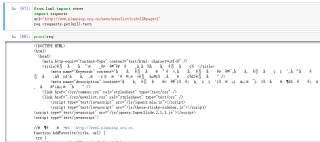
重网站里面爬取一些内容,显示中文的地方全是乱码,这个该怎么解决
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
谛凌
2022-02-23 15:38
关注
需要换一下编码
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
如何用
Python
编写一个简单的爬虫进行数据挖掘(基于
Jupyter
NoteBook
)
2021-04-23 22:57
泽楷学量化的博客
如何用
Python
编写一个简单的爬虫进行数据挖掘(基于
Jupyter
NoteBook
) 引言: 该文章将会从极其简略的角度去说明如何搭建一个爬虫对目标数据,有效信息进行挖掘,并且将小编在自学中遇到的一些问题进行引出和附上
解决
...
解决
jupyter
中文显示
乱码
问题
2023-04-15 21:58
LovEShot6的博客
有个问题就是第六行'font.family'的问题,我参考了别人的博客,发现可以自己列出来font.family来选择字体。大概就这样稀里糊涂的
解决
了吧。
Python
乱码
原理及其
解决
办法
2023-04-26 18:46
Jacky&Jacky的博客
Python
乱码
原理及其
解决
办法 HTML 解析 爬虫 编码 解码
乱码
python
爬取书趣阁小说
2020-04-19 22:45
我每天都好困.的博客
我们在请求服务器之前要先看一下这个网页的构造,我们可以看到它的信息全部都是通过html加载出来的,每一个url 都可以对应一篇小说,所以我们只需要提取到该小说目录的所有链接就可以获取到没有个章节的
内容
了。...
爬取豆瓣TOP250
2020-04-13 08:06
zhou_tong9的博客
第一课《爬取豆瓣TOP250》一、准备工作二、开始分析网页(1)URL链接分析网页(2)用for循环分析(3)用函数表示出URL链接三、
爬取网页
(1)安装requests库(2)在网页上对代码进行审查(3)请求源代码(HTML),向...
【
python
数据分析】爬取气象局+图表可视化
2024-08-02 11:19
学着吃鱼(妮妮版)的博客
x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36' } res=requests.get(url,headers) #
解决
乱码
content=res.content.decode('utf-8') print(content) 四、分析 #当请求的数据得到的...
Python
网络爬虫入门笔记1
2023-07-10 00:19
念惜`的博客
使用程序:
jupyter
notebook
语言:
Python
3
jupyter
中 Markdown用来写笔记,同
时
能写html代码,Code用来写代码 特性:代码编写顺序无所谓,执行顺序一定是自上而下的。(只要在一个cell中执行定义好多变量函数等,...
Miniconda-
Python
3.9环境下使用BeautifulSoup
爬取网页
2025-12-30 17:20
青菜炒蛋的博客
通过Miniconda创建独立
Python
环境,结合BeautifulSoup与requests高效提取网页数据,
解决
编码、动态加载与反爬等常见问题,实现稳定可复现的爬虫开发流程。
python
爬取网页
network_网络数据抓取-Header-Boss直聘-
Python
-requests爬虫
2020-12-03 06:53
weixin_39992788的博客
零基础十分钟上手网络数据抓取-
Python
-爬虫这一篇我们看一下更复杂的情况,爬取Boss直聘这个招聘网站的招聘信息,进而简单分析人工智能行业的招聘情况。1. 理解页面打开这个页面,这是Boss直聘网站苏州搜索“人工智能...
使用
jupyter
-
notebook
+
python
+ matplotlib 进行数据可视化
2019-09-28 19:29
weixin_30768661的博客
上次用
python
脚本中定期查询数据库,监视订单变化,将
时
间与处理完成订单的数量进行输入写入日志,虽然省掉了人为定
时
查看数据库并记录的操作,但是数据不进行分析只是数据,要让数据活起来! 为了方便看出已完成...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
3月5日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
2月25日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
2月23日

 分享
分享 系统已结题
3月5日
系统已结题
3月5日 已采纳回答
2月25日
创建了问题
2月23日
已采纳回答
2月25日
创建了问题
2月23日


