收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
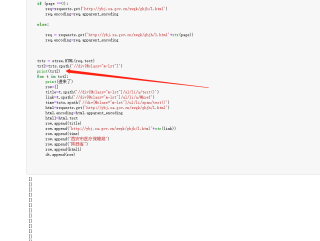
那说明你参数填错了呗先打印源码,看里面div到底是怎么写的,然后对应的去写不要凭想象
报告相同问题?

 分享
分享 已结题
(查看结题原因) 6月21日
创建了问题
2月25日
已结题
(查看结题原因) 6月21日
创建了问题
2月25日




