我在学习hadoop的过程中,在虚拟机中下载hive,之后将mysql-connector-java-5.1.46-bin.jar拷贝到hive/lib目录下,但是启动hive的时候,出现以下错误,有没有大神知道怎么解决。(我是在启动hadoop之后启动hive)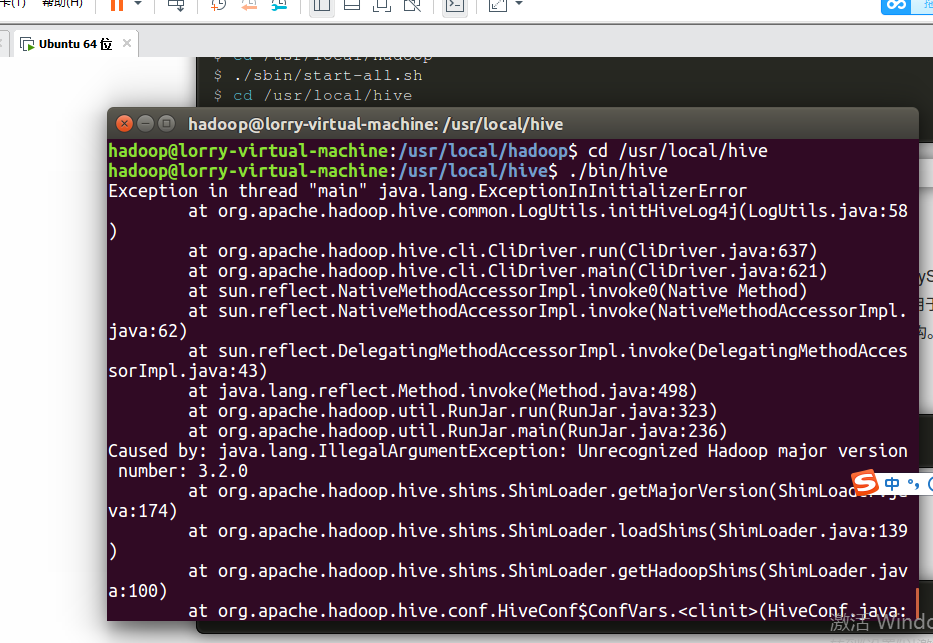

Hive错误: Unrecognized Hadoop major version number: 3.2.0

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

- 谵忆南的博客 Caused by: java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.0.0-cdh6.2.1 业务场景:spark 抽取ck数据进Hive 结论:CDH 自带的hive 版本和hadoop支持的hive 版本对应不上 导致...
- 我要用代码向我喜欢的女孩表白的博客 spark使用hive中有比较多的坑,尤其是版本问题引起的jar包冲突,比较好的方式是使用与CDH匹配的hive和hadoop版本,这样可以减少很多的jar冲突问题,但是在IDEA调试过程中还是难免会碰到jar包冲突问题。...
- 2023-08-18 10:24远方有海,小样不乖的博客 spark提交job到yarn报错,业务代码比较简单,通过接口调用获取数据,将数据通过sparksql将数据写入hive中,尝试各种替换hadoop版本,最后拿下。2.项目 pom.xml。将相关依赖不打进包中。1.hadoop环境。3.项目集群提交...
- 2021-02-11 11:30itwebber的博客 环境:Ubuntu14.04 Hadoop3.2.0 MySQL5.7 hive2.3.6安装步骤:安装hive、MySQL并进行配置安装过程中出现很多问题:1.hive版本问题:Unrecognized Hadoop major version number: 3.x.x exception;原因:第一次安装...
- 2019-03-02 11:47逝水-无痕的博客 文章目录1、在Hive cli中往...Unrecognized Hadoop major version number: 3.2.0 当时环境版本信息: hadoop版本:3.2.0 spark版本:2.4.0 hive版本:3.1.1 解决方案: 版本兼容性问题,通过查看hive源码根...
- 2020-07-02 18:55渣男程序员007的博客 mysql-connector-java-5.1.39.jar(驱动,需要放入/hive/lib) apache-hive-1.2.1-bin.tar.gz 2.安装mysql 数据用于储存元数据,hive自带Derby,但该数据库不稳定,使用mysql作为元数据管理 1). 只需要安装在集群里面...
- 2019-08-07 10:34Chungchinkei的博客 Hadoop版本:Hadoop3.2.0 MySQL版本:MySQL5.7 Hive的安装基于Hadoop,因此需要先搭建好Hadoop环境,详细可见:CentOS7 + Hadoop 3.2.0集群搭建; 其次以MySQL作为Hive的元数据库,所以也要先安装好MySQL,详见:...
- 2025-06-17 20:38老四敲代码的博客 INFO] 2024-09-25 06:19:16.083 +0000 - -> 注: /tmp/sqoop-root/compile/46c0c4b3def5aba0c202ae9664234de6/QueryResult....再出现错误按照下边的格式进行修改。在文档的最下边添加下边的代码。配置完成后,重启 ds。
- 2020-01-09 12:54猫不夜行的博客 写在前面 本文介绍了一次Flink-1.9.1集成...注意:Flink官方表示目前Flink集成Hive仅支持2.3.4和1.2.1两个版本,我在利用CDH-6.1.0-Hadoop-3.0.0(Hive-2.1.1)集群集成Hive过程中发现,无论配置2.3.4和1.2.1都会出...
- 2020-07-08 15:39wyju的博客 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/data/hive/lib/log4j-slf4j-...SLF4J: Found binding in [jar:file:/data/hadoop-3.2.0/hadoop-3.2.0/share/hadoop/common/
- 没有解决我的问题, 去提问
