例如http://12366.beijing.chinatax.gov.cn:8080/
如何利用excel表格中的关键词通过上面网址搜索
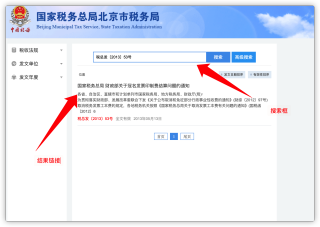
得出结果后点击链接,复制页面的文字收集到excel或word都可以
感谢各位!!最好是mac系统的解法,excel VBA ,python也可以,感谢!

例如http://12366.beijing.chinatax.gov.cn:8080/
如何利用excel表格中的关键词通过上面网址搜索
 分享
分享
用 pandas 读取excel内的关键词,并用 requests获取指定网页中搜索结果
你题目的解答代码如下:
import pandas as pd
import requests
df = pd.read_excel('xxx.xlsx')
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
"Host": "12366.beijing.chinatax.gov.cn:8080",
"Origin": "http://12366.beijing.chinatax.gov.cn:8080",
"Pragma": "no-cache",
"Referer": "http://12366.beijing.chinatax.gov.cn:8080/",
"X-Requested-With": "XMLHttpRequest",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
}
li = []
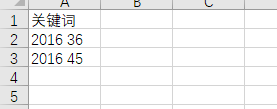
for v in df['关键词']:
print(v)
data = {
"page": "1",
"pageSize": "5",
"zltype": "1",
"zlflag": "1",
"keywords": v,
"order": "",
"sortField": ""
}
url = "http://12366.beijing.chinatax.gov.cn:8080/zsk/zsksearch/search"
r = requests.post(url, data=data, headers=headers)
res = r.json()
if 'pageContent' in res and len(res['pageContent'])>0:
title = res['pageContent'][0]['TITLE']
zlnr = res['pageContent'][0]['ZLNR']
li.append(title+" "+zlnr)
else:
li.append("没有搜索结果")
print(li)
df['搜索结果'] = li
df.to_excel(r'xxx2.xlsx',index=None)
读取的excel

如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!
分享 系统已结题
3月9日
系统已结题
3月9日 已采纳回答
3月1日
创建了问题
2月28日
已采纳回答
3月1日
创建了问题
2月28日


