实在找不到原因1,这csdn也够可以的,还有字数限制。30个字才行。哭了
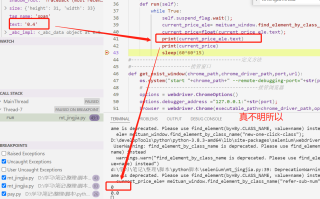
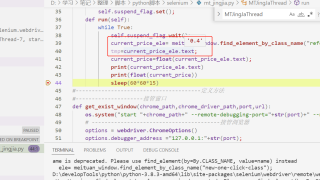
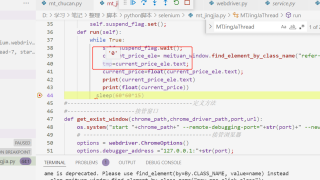
神奇不!

实在找不到原因1,这csdn也够可以的,还有字数限制。30个字才行。哭了
 分享
分享
把报错贴出来,
最简单就是加try, 把错误的值打出来
分享 已结题
(查看结题原因) 3月2日
已采纳回答
3月2日
修改了问题
3月2日
创建了问题
3月2日
已结题
(查看结题原因) 3月2日
已采纳回答
3月2日
修改了问题
3月2日
创建了问题
3月2日

