



2条回答 默认 最新
 CSDN专家-showbo 2022-03-08 09:03关注
CSDN专家-showbo 2022-03-08 09:03关注第二个li的div下少了结束标签导致etree解析出错了
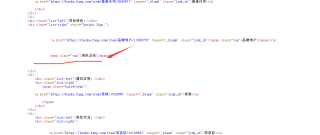
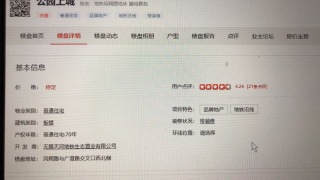
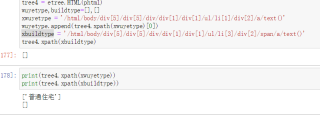
少了div结束标签后,etree将建筑类别后的几点全部归类到第二li下了,改下面这样就可以了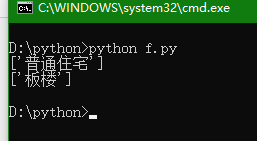
import requests from lxml import etree from lxml import html url="https://wuxi.newhouse.fang.com/loupan/1821129836/housedetail.htm" headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'} html=requests.get(url,headers=headers).text tree=etree.HTML(html) print(tree.xpath('/html/body/div[5]/div[5]/div/div[1]/div[1]/ul/li[1]/div[2]/a/text()')) print(tree.xpath('/html/body/div[5]/div[5]/div/div[1]/div[1]/ul/li[2]/div[2]/li[1]/div[2]/span/a/text()'))这种不规则的html代码建议用正则或者bs4来解析。
 本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 2无用举报 编辑记录
本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 2无用举报 编辑记录 分享
分享
- 2024-03-19 23:24hjc_042043的博客 XPath 使用路径表达式来选取 XML 文档中的节点或节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常类似。使用chrome 插件选择标签时候,选中时,选中的标签会添加属性class=“xh-highlight”
- 2025-07-15 14:36通过本文所介绍的Python中XPath爬虫实例,读者可以掌握如何利用Python进行基本的网页数据提取,为后续的学习和开发打下坚实的基础。无论你是初学者,还是有一定的编程经验,通过实践这些实例代码,都将加深你对网络...
- 2020-09-18 18:18主要介绍了python实例:xpath爬虫实例,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下
- 2023-12-29 12:13景天科技苑的博客 xpath表达式如何理解?html中的标签是遵从树状结构的。切记:xpath表达式中最好不要出现tbody标签,因为tbody标签可能是浏览器加的,可以通过查看网页源代码判断是否是真实的tbody!tbody可能是源代码自带的,也有...
- 2022-08-01 19:59阿浩( ̄▽ ̄)的博客 XPath是一门在XML文档中查找信息的语言,最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。所以在Python爬虫中,我们经常使用xpath解析这种高效便捷的方式来提取信息。
- 2024-06-14 15:01通过使用Python爬虫以及XPath Helper插件,我们可以轻松地获取目标网页上的图片链接。在使用XPath表达式时,我们可以先通过谷歌浏览器安装XPath插件,随后在爬虫程序中调用XPath表达式,解析网页排版结构,从而准确...
- 2020-07-10 18:23猛男技术控的博客 xpath是学爬虫的必备工具,其选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以...
- 2022-01-01 19:43境里婆娑的博客 所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。 二、安装lxml lxml是Python的一个第三方解析库,支持HTML和XML解析,而且效率非常高,弥补了Python自带的xml标准库在XML解析方面的不足。 由于是第三方库...
- 2022-07-29 09:50万里顾—程的博客 可以用xpath插件来动态的获取xpath路径(将鼠标悬停在需要选取的...4、调用xpath路径,提取数据,xpath的返回数据是列表类型。2、发送请求访问网站,得到服务器响应的页面源码。使用实例二从网站上下载图片。.......
- 2023-12-11 10:43StaysOnEarth的博客 urllib.request.urlopen(request) content = response.read().decode('gb2312') # 获取源码中的数据 from lxml import etree tree = etree.HTML(content) # //td[@class="align_left"]/text() result = tree.xpath('...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
3月18日
系统已结题
3月18日 已采纳回答
3月10日
已采纳回答
3月10日-
创建了问题
3月8日