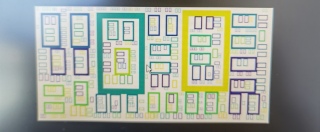
为啥我的词云制作出来是这个效果?!另外wordcloud制作词云是以空格或者标点符号分割的吧?包括"\n"?

 分享
分享
 关注
关注显示中文的问题,要设置一下font_path='simhei.ttf',下面给你一个常用的wordcloud绘制中文词云的模板,从txt里读取,你数据如果在csv那就取那一列统计。
import jieba
import collections
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 你的txt里的数据
with open('datas.txt') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('stop_words.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
# 筛选后统计
word_counts = collections.Counter(result_list)
# 绘制词云
my_cloud = WordCloud(
background_color='white', # 设置背景颜色 默认是black
width=800, height=550,
font_path='simhei.ttf', # 设置字体 显示中文
max_font_size=112, # 设置字体最大值
min_font_size=12, # 设置子图最小值
random_state=80 # 设置随机生成状态,即多少种配色方案
).generate_from_frequencies(word_counts)
# 显示生成的词云图片
plt.imshow(my_cloud, interpolation='bilinear')
# 显示设置词云图中无坐标轴
plt.axis('off')
plt.show()
stopwords.txt数据可以通过链接获取:https://musetransfer.com/s/2ytqsm28p
分享 系统已结题
3月17日
系统已结题
3月17日 已采纳回答
3月9日
创建了问题
3月9日
已采纳回答
3月9日
创建了问题
3月9日

