import urllib.parse
import urllib.request
def create_request(page):
base_url = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%83%AD%E9%97%A8&sort=recommend&%27
data = {
'page_limit' : 20,
'page_start' : (page-1)*20
}
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban_'+str(page)+'.json','w',encoding='utf-8')as fp:
fp.write(content)
if name == 'main':
start_page = int(input('请输入起始页值'))
end_page = int(input('请输入结束页值'))
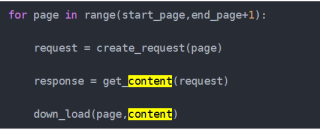
for page in range(start_page,end_page+1):
request = create_request(page)
response = get_content(request)
down_load(page,content)