问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
job_list = tree.xpath('//div[@class = "j_joblist"]/div/a/p/span/text()')
print(job_list)
运行结果及报错内容



job_list = tree.xpath('//div[@class = "j_joblist"]/div/a/p/span/text()')
print(job_list)
 分享
分享
你先输出一下request+s爬取的数据,看看是否有你需要爬取的内容
你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
用F12查看到的代码是通过js动态更新后的内容,
要查看网页的静态源代码应该在页面上点击右键,右键菜单中选 "查看网页源代码"。
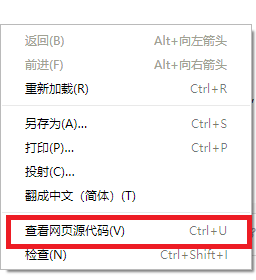
如果这个网页的静态源代码中有你需要爬取的内容,但requests获取的内容中却没有,可能是requests伪造的头部信息不全。
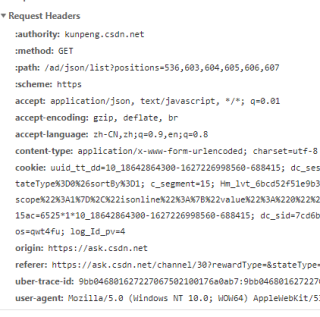
要在headers中添加抓包时的请求头求参数
比如
url = "https://xxxxxxxxxxx"
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!
分享 系统已结题
3月22日
系统已结题
3月22日 已采纳回答
3月14日
创建了问题
3月14日
已采纳回答
3月14日
创建了问题
3月14日



