刚入门爬虫爬取网页解析下载页面图片,报错不知道怎么解决啊 怎么通过审核这么难
收起
看看这个 urlretrieve的用法_CSDN_Xying的博客-CSDN博客_urlretrieve什么意思 urlretrieve用作下载网页上的图片def urlretrieve(url, filename=None, reporthook=None, data=None):url : 需要保存的内容url,在网页上查询到想要的数据,filename : 需要保存的地址,路径及名称 urllib.request.urlretrieve(cover_url,filename='../do... https://blog.csdn.net/CSDN_Xying/article/details/97939501
报告相同问题?
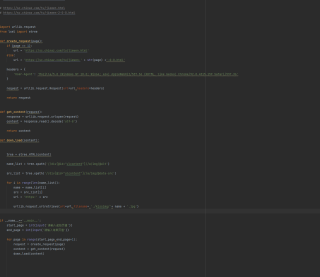
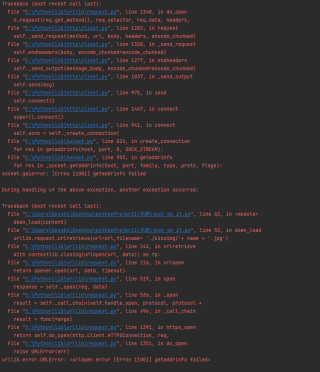

 分享
分享 系统已结题
3月26日
系统已结题
3月26日 已采纳回答
3月18日
修改了问题
3月18日
修改了问题
3月18日
已采纳回答
3月18日
修改了问题
3月18日
修改了问题
3月18日


