
使用自己的数据进行tensorflow相关实验时发现 tf.convert_to_tensor(data)报错,提示需要的是二进制或字符串而data是一个['...','..',...]形式的数据
而label则能跑通
输入的文件是4002个浮点数一行,共8400行,前4000个是data,后两个表示label
最主要的是通过对函数返回的data和label使用shape函数得到的结果却大不一样!
先附上代码
def loadDataSet(filename):
dataL = []
labelL = []
fr = open(filename)
#for line in fr.readlines():
for i in range(100):
line = fr.readline()
lineArr = line.strip().split(' ')
npy = array(lineArr)
dataL.append(npy[:-2])
labelL.append(npy[-2:])
fr.close()
data = array(dataL)
label = array(labelL)
print(len(data),len(label))
return data,label
t_x,t_y = loadDataSet('rand_out.txt')
train_y = tf.convert_to_tensor(t_y)
print(type(train_y))
print(type(t_y))
print(type(t_x))
print(len(t_x[0]))
print(len(t_y[0]))
print(t_x.shape)
print(t_y.shape)
发现在上述代码中循环变量i的取值范围直接影响print的输出结果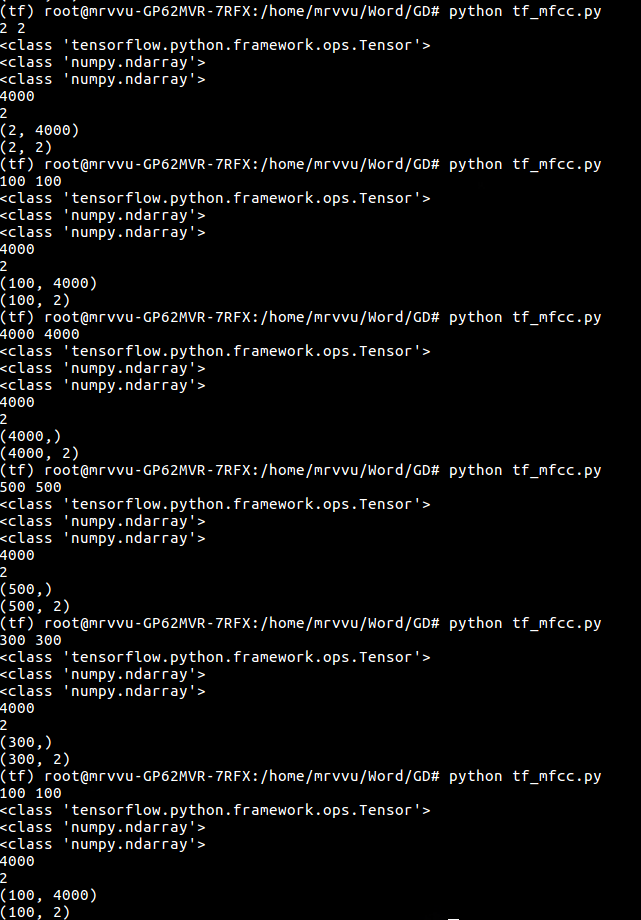
可以看出i的循环范围大于某个数后,data也就是上面代码中的t_x.shape输出从(int,int)变成了(int,)
即for i in range(4000)时,shape是(4000,);for i in range(100)时,shape是(100,4000)






