
理论上来说,不是说一种key对应一个reduce吗,但是为什么我这样跑一个任务,对应的key应该是data_dt吧,但是data_dt也没有1000多个呀,为什么有1000多个reduce呢?
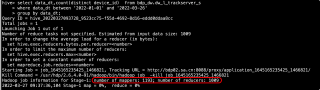

理论上来说,不是说一种key对应一个reduce吗,但是为什么我这样跑一个任务,对应的key应该是data_dt吧,但是data_dt也没有1000多个呀,为什么有1000多个reduce呢?
 分享
分享
可以设置reduce的参数的
set mapreduce.reduce.tasks
可以直接设置有多少个task
如果没有指定reduce个数,
通过hive.exec.reduces.bytes.per.reducer参数来设定每个reducer处理的bytes。
这个参数越大,reducer就越少。
分享 系统已结题
4月4日
系统已结题
4月4日 已采纳回答
3月27日
创建了问题
3月27日
已采纳回答
3月27日
创建了问题
3月27日


