
问题遇到的现象和发生背景 :
用Python爬取一个网页,这个网页的特点是如果向下滚动,会源源不断的生成
标签,没有尽头,如果爬取这个网页,生成器
标签爬取下来之后只有只有个loading,而我想要获得的就是这些生成的
标签,应该怎么办?
问题相关代码:
问题相关代码:
import urllib.request,urllib.error# 制定URL,获取网页数据
def askUrl(url):
head = {# 模拟浏览器头部信息,想浏览器发送消息
"authority": "cupfox.app",
"method": "GET",
"scheme": "https",
"path":"/ list?category = % E7 % 83 % AD % E6 % 92 % AD % E6 % 96 % B0 % E5 % 89 % A7",
"user-agent": "Mozilla / 5.0(Linux;Android 6.0;Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 99.0.4844.74 bile Safari / 537.36 Edg / 99.0.1150.55"
}# 告诉服务器,我们能够接受什么类型的内容
request = urllib.request.Request(url,headers=head) #把URL和头部信息headers封装成一个request对象赋给request,
html = ''# 定义一个对象,用于封装服务器返回的数据
#爬取网页的时候,可能会遇到很多问题,这时候需要进行异常处理:
try:
response = urllib.request.urlopen(request,timeout=100) # 把封装的request对象发送给服务器,告诉它我们要打开一个URL,并且我们能够接收的类型在head里面有说明,timeout是超时时间,如果超过10秒服务器没有响应,判定为超时
html = response.read().decode('utf-8')#读取服务器返回的数据,因为数据经过utf-8编码,所以需要decode解码
except urllib.error.URLError as e :
if hasattr(e,"code"):
print(e.code) # 把有什么问题打印出来
if hasattr(e,"reason"):
print(e.reason)# 把什么原因没有获取成功打印出来
return html
print(askUrl("https://cupfox.app/list?category=%E7%83%AD%E6%92%AD%E6%96%B0%E5%89%A7"))
运行结果及报错内容 :
网页如果向下滑动网页会源源不断的生成div标签:
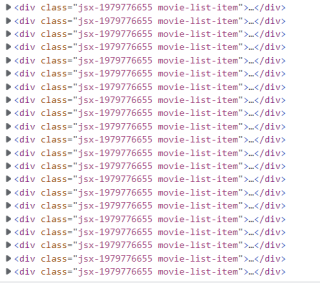
下面是爬取到的内容
<title id="qr5y417-aria">Loading.</title>






