
小弟最近在看OpenCV+TensorFlow这本书的案例
照着输进去了结果发现运行不下去,
问题应该是出现在第二块内容,但是真的不太明白!求各位大神赐教,如何修改!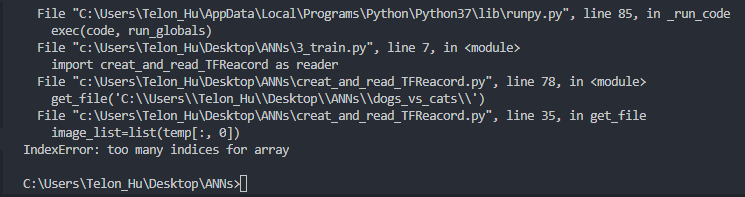
第一块,修改照片尺寸,为啥呀
import cv2
import os
def resize(dir):
for root, dirs, files in os.walk(dir):
for file in files:
filepath = os.path.join(root, file)
try:
image = cv2.imread(filepath)
dim = (227, 227)
resized = cv2.resize(image, dim)
path = "C:\\Users\\Telon_Hu\\Desktop\\ANNs\\train1\\" + file
cv2.imwrite(path, resized)
except:
print(filepath)
# os.remove(filepath)
cv2.waitKey(0)
resize('C:\\Users\\Telon_Hu\\Desktop\\ANNs\\train')
import os
import numpy as np
import tensorflow as tf
import cv2
def get_file(file_dir):
images=[]
temp=[]
for root,sub_folders,files in os.walk(file_dir):
'''
os.walk(path)---返回的是一个三元组(root,dirs,files):
root 所指的是当前正在遍历的这个文件夹的本身的地址
dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
'''
for name in files:
images.append(os.path.join(root,name))
for name in sub_folders:
temp.append(os.path.join(root,name))
labels=[]
for one_folder in temp:
n_img=len(os.listdir(one_folder)) #s.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
letter=one_folder.split('\\')[-1] #split() 通过指定分隔符对字符串进行切片,默认为-1, 即分隔所有。
if letter=='cat':
labels=np.append(labels,n_img*[0])
else:
labels=np.append(labels,n_img*[1])
temp=np.array([images, labels])
temp=temp.transpose() #矩阵转置
np.random.shuffle(temp) #随机排序
image_list=list(temp[:, 0])
label_list=list(temp[:, 1])
label_list=[int(float(i)) for i in label_list]
return image_list,label_list
def get_batch(image_list,label_list,img_width,img_height,batch_size,capacity):
image=tf.cast(image_list,tf.string)
label=tf.cast(label_list,tf.int32)
input_queue=tf.train.slice_input_producer([image,label])
label=input_queue[1]
image_contents=tf.read_file(input_queue[0]) #通过图片地址读取图片
image=tf.image.decode_jpeg(image_contents,channels=3) #解码图片成矩阵
image=tf.image.resize_image_with_crop_or_pad(image,img_width,img_height)
'''
tf.image.resize_images 不能保证图像的纵横比,这样用来做抓取位姿的识别,可能受到影响
tf.image.resize_image_with_crop_or_pad可让纵横比不变
'''
image=tf.image.per_image_standardization(image) #将图片标准化
image_batch,label_batch=tf.train.batch([image,label],batch_size=batch_size,num_threads=64,capacity=capacity)
'''
tf.train.batch([example, label], batch_size=batch_size, capacity=capacity):
1.[example, label]表示样本和样本标签,这个可以是一个样本和一个样本标签
2.batch_size是返回的一个batch样本集的样本个数
3.num_threads是线程
4.capacity是队列中的容量。
'''
label_batch=tf.reshape(label_batch,[batch_size])
return image_batch,label_batch
def one_hot(labels):
'''one-hot 编码'''
n_sample=len(labels)
n_class=max(labels)+1
onehot_labels=np.zeros((n_sample,n_class))
onehot_labels[np.arange(n_sample),labels]=1
return onehot_labels
get_file('C:\\Users\\Telon_Hu\\Desktop\\ANNs\\dogs_vs_cats\\')
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import time
import os
import sys
import creat_and_read_TFReacord as reader
x_train,y_train=reader.get_file('dogs_vs_cats')
image_batch,label_batch=reader.get_batch(x_train,y_train,227,227,50,2048)
#Batch_Normalization正则化
def batch_norm(inputs,is_train,is_conv_out=True,decay=0.999):
scale=tf.Variable(tf.ones([inputs.get_shape()[-1]]))
beta = tf.Variable(tf.zeros([inputs.get_shape()[-1]]))
pop_mean = tf.Variable(tf.zeros([inputs.get_shape()[-1]]), trainable=False)
pop_var = tf.Variable(tf.ones([inputs.get_shape()[-1]]), trainable=False)
if is_train:
if is_conv_out:
batch_mean, batch_var = tf.nn.moments(inputs, [0, 1, 2])
else:
batch_mean, batch_var = tf.nn.moments(inputs, [0])
train_mean = tf.assign(pop_mean, pop_mean * decay + batch_mean * (1 - decay))
train_var = tf.assign(pop_var, pop_var * decay + batch_var * (1 - decay))
with tf.control_dependencies([train_mean, train_var]):
return tf.nn.batch_normalization(inputs,
batch_mean, batch_var, beta, scale, 0.001)
else:
return tf.nn.batch_normalization(inputs,
pop_mean, pop_var, beta, scale, 0.001)
with tf.device('/gpu:0'):
# 模型参数
learning_rate = 1e-4
training_iters = 200
batch_size = 50
display_step = 5
n_classes = 2
n_fc1 = 4096
n_fc2 = 2048
# 构建模型
x = tf.placeholder(tf.float32, [None, 227, 227, 3])
y = tf.placeholder(tf.float32, [None, n_classes])
W_conv = {
'conv1': tf.Variable(tf.truncated_normal([11, 11, 3, 96], stddev=0.0001)),
'conv2': tf.Variable(tf.truncated_normal([5, 5, 96, 256], stddev=0.01)),
'conv3': tf.Variable(tf.truncated_normal([3, 3, 256, 384], stddev=0.01)),
'conv4': tf.Variable(tf.truncated_normal([3, 3, 384, 384], stddev=0.01)),
'conv5': tf.Variable(tf.truncated_normal([3, 3, 384, 256], stddev=0.01)),
'fc1': tf.Variable(tf.truncated_normal([6 * 6 * 256, n_fc1], stddev=0.1)),
'fc2': tf.Variable(tf.truncated_normal([n_fc1, n_fc2], stddev=0.1)),
'fc3': tf.Variable(tf.truncated_normal([n_fc2, n_classes], stddev=0.1))
}
b_conv = {
'conv1': tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[96])),
'conv2': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[256])),
'conv3': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[384])),
'conv4': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[384])),
'conv5': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[256])),
'fc1': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[n_fc1])),
'fc2': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[n_fc2])),
'fc3': tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[n_classes]))
}
x_image = tf.reshape(x, [-1, 227, 227, 3])
# 卷积层 1
conv1 = tf.nn.conv2d(x_image, W_conv['conv1'], strides=[1, 4, 4, 1], padding='VALID')
conv1 = tf.nn.bias_add(conv1, b_conv['conv1'])
conv1 = batch_norm(conv1, True)
conv1 = tf.nn.relu(conv1)
# 池化层 1
pool1 = tf.nn.avg_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID')
norm1 = tf.nn.lrn(pool1, 5, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
# 卷积层 2
conv2 = tf.nn.conv2d(pool1, W_conv['conv2'], strides=[1, 1, 1, 1], padding='SAME')
conv2 = tf.nn.bias_add(conv2, b_conv['conv2'])
conv2 = batch_norm(conv2, True)
conv2 = tf.nn.relu(conv2)
# 池化层 2
pool2 = tf.nn.avg_pool(conv2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID')
# 卷积层3
conv3 = tf.nn.conv2d(pool2, W_conv['conv3'], strides=[1, 1, 1, 1], padding='SAME')
conv3 = tf.nn.bias_add(conv3, b_conv['conv3'])
conv3 = batch_norm(conv3, True)
conv3 = tf.nn.relu(conv3)
# 卷积层4
conv4 = tf.nn.conv2d(conv3, W_conv['conv4'], strides=[1, 1, 1, 1], padding='SAME')
conv4 = tf.nn.bias_add(conv4, b_conv['conv4'])
conv4 = batch_norm(conv4, True)
conv4 = tf.nn.relu(conv4)
# 卷积层5
conv5 = tf.nn.conv2d(conv4, W_conv['conv5'], strides=[1, 1, 1, 1], padding='SAME')
conv5 = tf.nn.bias_add(conv5, b_conv['conv5'])
conv5 = batch_norm(conv5, True)
conv5 = tf.nn.relu(conv5)
# 池化层5
pool5 = tf.nn.avg_pool(conv5, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID')
reshape = tf.reshape(pool5, [-1, 6 * 6 * 256])
fc1 = tf.add(tf.matmul(reshape, W_conv['fc1']), b_conv['fc1'])
fc1 = batch_norm(fc1, True, False)
fc1 = tf.nn.relu(fc1)
# 全连接层 2
fc2 = tf.add(tf.matmul(fc1, W_conv['fc2']), b_conv['fc2'])
fc2 = batch_norm(fc2, True, False)
fc2 = tf.nn.relu(fc2)
fc3 = tf.add(tf.matmul(fc2, W_conv['fc3']), b_conv['fc3'])
# 定义损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=fc3))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(loss)
# 评估模型
correct_pred = tf.equal(tf.argmax(fc3,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.global_variables_initializer()
def onehot(labels):
'''one-hot 编码'''
n_sample = len(labels)
n_class = max(labels) + 1
onehot_labels = np.zeros((n_sample, n_class))
onehot_labels[np.arange(n_sample), labels] = 1
return onehot_labels
save_model = ".//model//AlexNetModel.ckpt"
def train(opech):
with tf.Session() as sess:
sess.run(init)
train_writer = tf.summary.FileWriter(".//log", sess.graph) # 输出日志的地方
saver = tf.train.Saver()
c = []
start_time = time.time()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
step = 0
for i in range(opech):
step = i
image, label = sess.run([image_batch, label_batch])
labels = onehot(label)
acc=[]
sess.run(optimizer, feed_dict={x: image, y: labels})
loss_record = sess.run(loss, feed_dict={x: image, y: labels})
acc=sess.run(accuracy,feed_dict={x:image,y:labels})
print("now the loss is %f " % loss_record)
print("now the accuracy is %f "%acc)
c.append(loss_record)
end_time = time.time()
print('time: ', (end_time - start_time))
start_time = end_time
print("---------------%d onpech is finished-------------------" % i)
print("Optimization Finished!")
# checkpoint_path = os.path.join(".//model", 'model.ckpt') # 输出模型的地方
saver.save(sess, save_model)
print("Model Save Finished!")
coord.request_stop()
coord.join(threads)
plt.plot(c)
plt.xlabel('Iter')
plt.ylabel('loss')
plt.title('lr=%f, ti=%d, bs=%d' % (learning_rate, training_iters, batch_size))
plt.tight_layout()
plt.savefig('cat_and_dog_AlexNet.jpg', dpi=200)
train(training_iters)






