

问题遇到的现象和发生背景
写了一个程序,对源数据进行处理,并写入statistics.csv文件中。只输入数据没有任何问题:
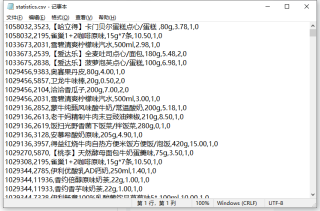
但我用.seek(0)将指针重置到statistics文件的开头,再写入标题行(对应下图代码末尾,第46-47行代码)就会多出不属于标题行内容的字符:
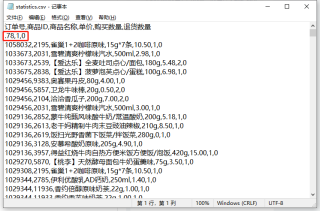
想问一下导致问题的原因以及解决方法
问题相关代码,请勿粘贴截图
def findsize(goodsname):
flag = 0
if re.search(r'\d',goodsname):
if goodsname.count('*'):
for i in range(1,len(goodsname)+1):
if not flag:
if goodsname[-i].isnumeric():
flag = 1
elif flag == 1:
if goodsname[-i].isnumeric():
flag = 2
if i == len(goodsname) or not goodsname[-(i+1)].isnumeric():
return goodsname[-i:]
break
else:
if i == len(goodsname) or not goodsname[-(i+1)].isnumeric():
return goodsname[-i:]
break
else:
for i in range(1,len(goodsname)+1):
if not flag:
if goodsname[-i].isnumeric():
not flag #如果在flag为False的前提下找到了数字,那么就将flag改为True,并执行寻找规格终点并输出的代码
if i == len(goodsname) or not goodsname[-(i+1)].isnumeric():
return goodsname[-i:]
break #更改flag的同时立刻再判断是否到了商品名称终点或者下一个字符是否为数字
elif i == len(goodsname) or not goodsname[-(i+1)].isnumeric():
return goodsname[-i:]
break
import re
import os
filelist = [filename for filename in os.listdir('data/sales/') if filename.startswith('2020')]
filew = open('data/sales/statistics.csv','wt',encoding = 'utf8')
for filename in filelist:
file = open('data/sales/'+filename,encoding = 'utf8')
line1 = file.readline()
for line in file:
flag = False
detailinfo = line.strip('\n').split(',')
goodsname = detailinfo[2]
if findsize(goodsname):
detailinfo.insert(3,findsize(goodsname))
detailinfo[2] = detailinfo[2].replace(findsize(goodsname),'')
filew.write(','.join(detailinfo)+'\n')
file.close()
filew.seek(0)
filew.write('订单号,商品ID,商品名称,单价,购买数量,退货数量\n')
filew.close()








