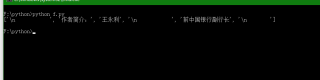
pycahrm打印时出错,无法用xpath后面加text()将内容打印下来
import requests
from lxml import etree
url = "http://finance.sina.com.cn/zl/china/2022-04-06/zl-imcwipii2061261.shtml"
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36',
'Host':'finance.sina.com.cn'
}
X = requests.get(url=url,headers=header)
X1 = X.content.decode('utf8')
result = etree.HTML(X1)
divresult = result.xpath('//div[@class="recommendCont"]//div[@class="rcdTopRigt"]/text()')[0]
divresults = etree.tostring(divresult,encoding='utf8').decode('utf8')
print(divresults)
divresults = etree.tostring(divresult,encoding='utf8').decode('utf8')
File "src\lxml\etree.pyx", line 3460, in lxml.etree.tostring
TypeError: Type 'lxml.etree._ElementUnicodeResult' cannot be serialized.
不知道为什么出现这个错误,希望能够给解答下