关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
KingHonour
2022-04-07 11:17
采纳率: 100%
浏览 652
首页
有问必答
已结题
python爬取到的网页文本,保存本地txt显示文件为空?什么原因呢?
有问必答
python
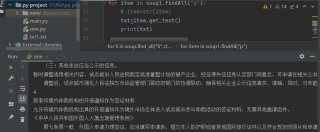
单纯打印的话,可以正常显示内容
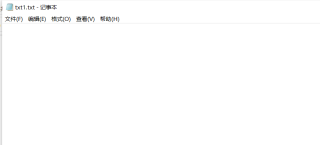
写入本地可以运行成功,但是打开txt文本,里面空空如也
是不是需要其它保存方式啊?
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
3
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
CSDN专家-showbo
2022-04-07 11:29
关注
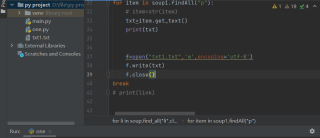
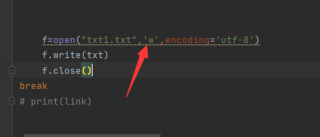
w改为a(追加),要不会将当前写入的内容覆盖文件内容
要么将open和close放到for循环外
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
2
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(2条)
向“C知道”追问
报告相同问题?
提交
关注问题
python
爬取
招聘网信息并
保存
为csv文件
2023-04-02 19:11
【
Python
爬虫获取招聘网站信息并
保存
为CSV文件】 在
Python
编程中,网络爬虫是一种常用的技术,用于自动化地从互联网上抓取信息。在这个场景中,我们将学习如何使用
Python
来
爬取
招聘网站上的职位信息,并将其存储为...
Python
爬取
网页
文字并
保存
为
txt
文件教程
2024-12-19 20:00
从以前的博客
将要
爬取
的
网页
网址赋值给变量url。
使用
python
的scrapy模块
爬取
文本
保存
到
txt
文件
2020-12-23 01:22
使用
python
的scrapy
爬取
文本
保存
为
txt
文件 编码工具 Visual Studio Code 实现步骤 1.创建scrapyTest项目 在vscode中新建终端并依次输入下列代码: scrapy startproject scrapyTest cd scrapyTest code 打开项目...
python
爬取
网页
内容生成html文件_
python
爬取
HTML内容并
保存
到
txt
文件内
2020-12-17 02:25
weixin_39692253的博客
# @UpdateTime : 2020-12-08 16:53# @Author : wz# @File : Get_WebDetails# @Software: PyCharm# @used:
爬取
任意页面中任意数据import reimport urllib.requestfrom Utils.Log import LoggerLogger_message = ...
python
爬取
的数据存到
txt
文本
文件中。
2024-06-13 01:21
Clay-A的博客
首先咱们得有
python
基础并熟练使用
python
代码!
python
爬取
小说并存储为
txt
文件
2024-05-30 10:25
SimonLiu009的博客
使用
python
爬取
小说并存储为
txt
文件
python
如何获取
网页
源代码并
保存
本地_
python
爬取
csdn
网页
并
保存
博客到本地
2021-03-05 14:55
郭底迪的博客
这几天一直在学用
python
爬
网页
, 现在是用urllib2,cookie等模块获取了csdn的博客源码,然后打算把所有博客都
保存
到本地;这就涉及到了解析html, 由于对正则的理解不太深。。。就用了第三方工具模块:美丽的汤---...
如何使用
Python
爬取
多章节小说并
保存
为
文本
文件
2024-09-06 00:12
BARRY_NINE的博客
使用
Python
爬取
多章节小说
pandas借助
python
爬虫
爬取
网页
html表格
保存
到excel文件
2025-03-13 09:22
听海边涛声的博客
pandas借助
python
爬虫
爬取
网页
html表格
保存
到excel文件
python
爬取
文章
保存
为
txt
_
爬取
博主所有文章并
保存
到本地(.
txt
版)--
python
3.6
2020-12-11 13:42
weixin_39954487的博客
正好最近在学习
python
,刚刚从py2转到py3,还有点不是很习惯,正想着多练习,于是萌生了这个想法——用爬虫
保存
自己的所有文章在查了一些资料后,慢慢的有了思路。 正文:有了上面的思路后,编程就不是问题了,就像...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
4月15日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
4月7日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
4月7日


 分享
分享
 分享
分享 系统已结题
4月15日
系统已结题
4月15日 已采纳回答
4月7日
创建了问题
4月7日
已采纳回答
4月7日
创建了问题
4月7日


