爬取58同城招聘信息是xpath遇到空值。无法继续爬取。
import requests #导入requests库
from lxml import etree#导入lxml库
import csv#输出文件类型
import time#时间函数
def spider():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'}#定义头部
pre_url = 'https://hc.58.com/job/pn'#构造URL
for x in range(1,2):#使用for循环构造前几页URL地址并GET请求
html=requests.get(pre_url+str(x),headers=headers)
time.sleep(2)#休眠时间
selector = etree.HTML(html.text)#初始化etree
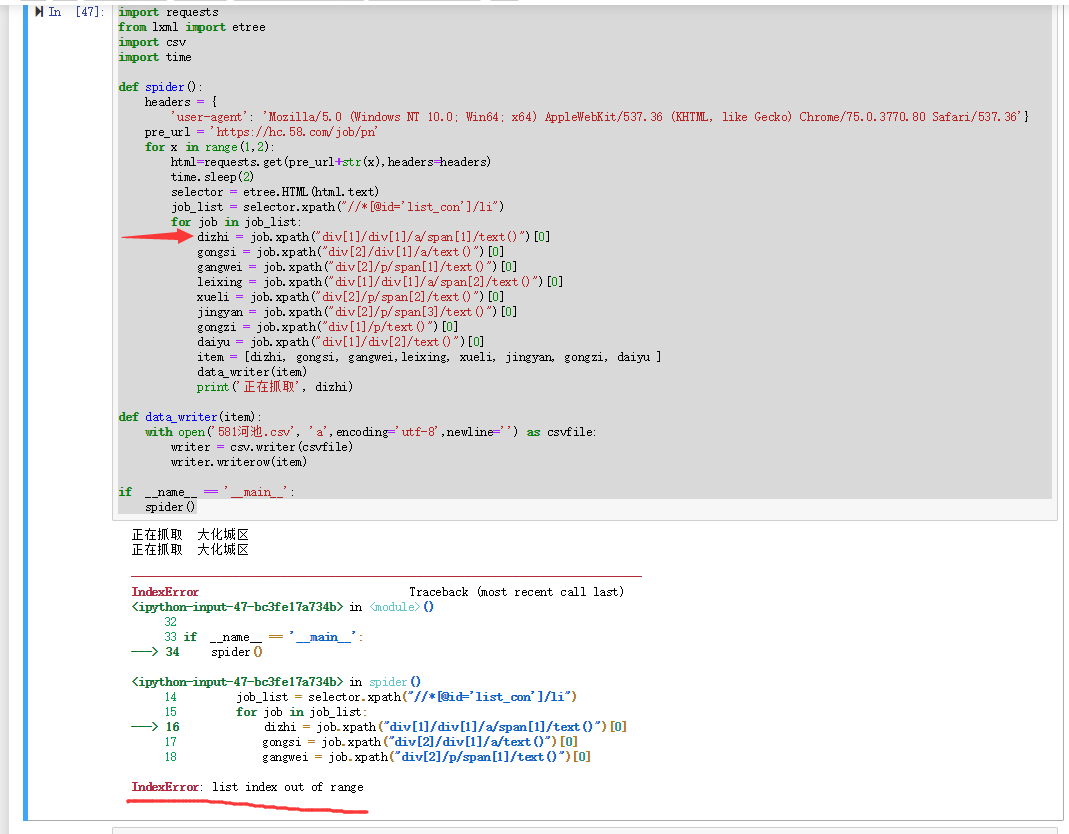
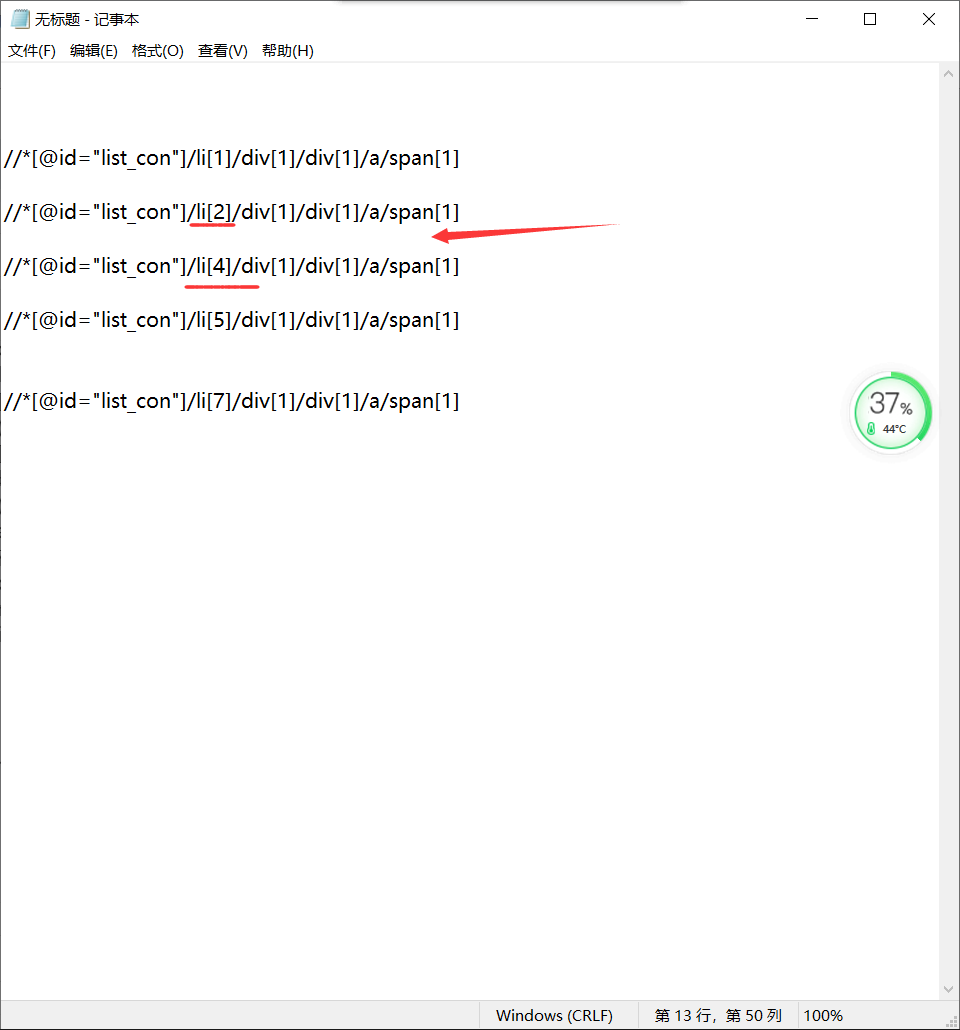
job_list = selector.xpath("//*[@id='list_con']/li")#获取工作列表
for job in job_list:
dizhi = job.xpath("div[1]/div[1]/a/span[1]/text()")[0]#公司地址
gongsi = job.xpath("div[2]/div[1]/a/text()")[0]#公司名称
gangwei = job.xpath("div[2]/p/span[1]/text()")[0]#所需岗位
leixing = job.xpath("div[1]/div[1]/a/span[2]/text()")[0]#人员类型
xueli = job.xpath("div[2]/p/span[2]/text()")[0]#员工学历
jingyan = job.xpath("div[2]/p/span[3]/text()")[0]#员工经验
gongzi = job.xpath("div[1]/p/text()")[0]#员工工资
daiyu = job.xpath("div[1]/div[2]/text()")[0]#福利待遇
item = [dizhi, gongsi, gangwei,leixing, xueli, jingyan, gongzi,daiyu ] #所要爬取的数据
data_writer(item)#保存数据
print('正在抓取', dizhi)
def data_writer(item):
with open('581河池.csv', 'a',encoding='utf-8',newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(item)
if __name__ == '__main__':#主函数
spider()