
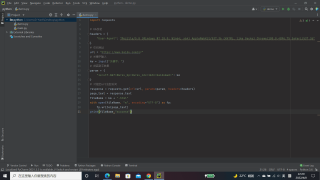
请问这是怎么回事啊
这个我找了很多地方,可还是不知道怎么去修改,才开始学,难以下手
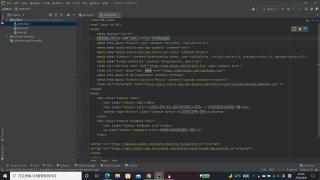

请问这是怎么回事啊
这个我找了很多地方,可还是不知道怎么去修改,才开始学,难以下手
 分享
分享
你requests 读取页面文件的编码不对 ,用 res.encoding='utf-8'或res.encoding='gbk'设置下读取页面文件用的编码, 再获取res.text即可,比如
res=requests.get('http://www.xxxx.com')
res.encoding='utf-8'
#或res.encoding='gbk'
print(res.text)
或者也可以设置 res.encoding=res.apparent_encoding 自动从网页的内容中分析网页编码
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!
分享 系统已结题
4月16日
系统已结题
4月16日 已采纳回答
4月8日
创建了问题
4月8日
已采纳回答
4月8日
创建了问题
4月8日



