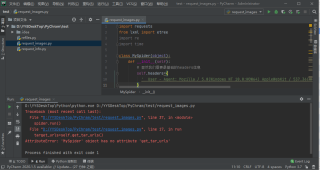
问题,在编写爬虫时遇到了类里面的属性调用报错,但是不知道是哪里出现了问题,请问怎么进行修改和处理呢
代码片段
import requests
from lxml import etree
import re
import time
class MySpider(object):
def init(self):
# 显然我们需要最基础的headers信息
self.headers={
' User - Agent: Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 86.0.4240.198Safari / 537.36'
}
# 其次我们需要url
self.url='http://www.bbsnet.com/doutu'
def run(self):
# 首先我们需要一个函数获取每一个url
target_urls=self.get_tar_urls()
# 其次我们需要去获取每一个url里面的图片
self.get_target_images(target_urls)
def get_target_urls(self):
response=requests.get(self.url,headers=self.headers)
text=response.content
html=etree.HTML(text)
target_urls=html.xpath('//h2/a/@href')
return target_urls
def get_tar_get_images(self,target_urls):
for url in target_urls:
response1=requests.get(url,headers=self.headers)
text1=response1.content.decode('utf-8')
print(text1)
break
if name=='main':
spider=MySpider()
spider.run()