1.问题描述:今天爬取凤凰财经http://finance.ifeng.com/shanklist/1-64-/
,使用scrapy shell调试的时候,无论我用什么样的css语法都没法提取到数据,百度不到这样的问题,只好来求助了
(是初学者,目前只会css; xpath和正则在学习中)
2.代码部分

1.问题描述:今天爬取凤凰财经http://finance.ifeng.com/shanklist/1-64-/
,使用scrapy shell调试的时候,无论我用什么样的css语法都没法提取到数据,百度不到这样的问题,只好来求助了
(是初学者,目前只会css; xpath和正则在学习中)
2.代码部分
 分享
分享
 关注
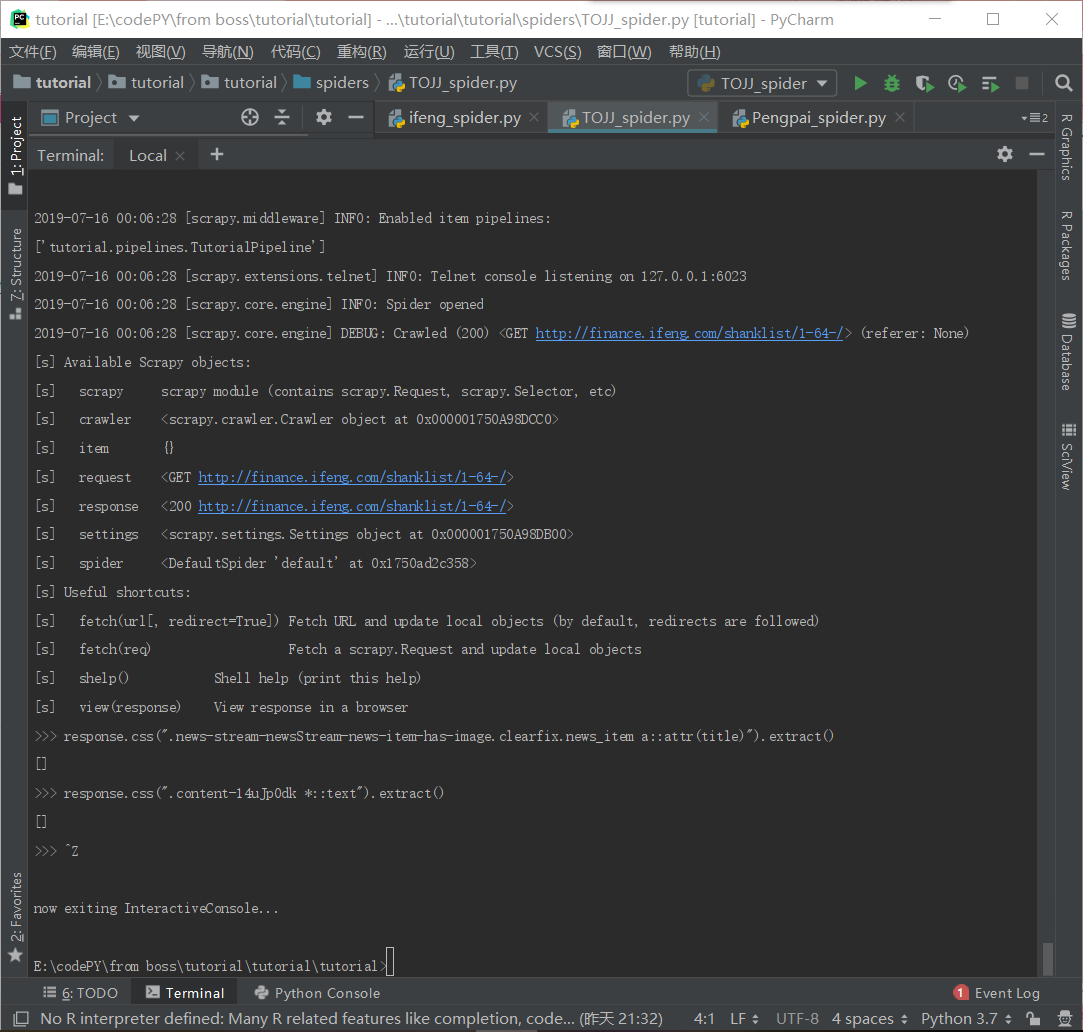
关注首先确认下获取到的响应文件中有没有数据,有些网站数据是动态加载的有可能你肯定就没有获取到数据 肯定就提取不到
如果确定有数据,在检查一下css语法有没有错误,
xpath很简单,正则最好用
分享




