from base64 import encodebytes
import requests
from bs4 import BeautifulSoup
import json
import pandas as pd
import time
#定义一个列表用来存储搜索页的url
url_List = []
# 自动遍历搜索页的网页链接赋值给变量url
count = 0
for i in range(51,100):
if i % 2 == 1:
page = i
for j in range(2+count,51):
s = 60*(j-1)-4
break
url1 = f"https://search.jd.com/search?keyword=%E8%8C%B6%E5%8F%B6&qrst=1&suggest=1.def.0.SAK7%7CMIXTAG_SAK7R%2CSAK7_M_AM_L5362%2CSAK7_M_COL_U17677%2CSAK7_S_AM_R%2CSAK7_SC_PD_LC%2CSAK7_SM_PB_L16675%2CSAK7_SS_PM_R%7C&wq=%E8%8C%B6%E5%8F%B6&stock=1&ev=16794_23998%5E&pvid=b155d2f5f40f48369d91e0f564d73400&page={page}&s={s}&click=0"
#time.sleep(1)
url_List.append(url1)
print(url_List)
else:
continue
count += 1
# 将User-Agent以字典键值对形式赋值给headers
# 将cookie以字典键值对形式赋值给headers
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
"cookie":"shshshfpa=56c4ea85-6617-6321-3988-48bc8627ced5-1647762254; shshshfpb=tu52dQndsgAvAyGFR7sFSOg; __jdu=16477622543171043297134; qrsc=3; __jdv=122270672|direct|-|none|-|1649579506824; areaId=25; ipLoc-djd=25-2291-3916-11084; pinId=bRvHN5JeiS0rc4hgd7chmw; pin=jd_xqRFFIAGIZXc; unick=jd_xqRFFIAGIZXc; _tp=9jCzs88r8gpbMSTXeXbCDQ%3D%3D; _pst=jd_xqRFFIAGIZXc; ip_cityCode=2291; __jda=122270672.16477622543171043297134.1647762254.1649933001.1649987947.20; __jdc=122270672; shshshfp=eccf123cfc5d84df3fc0dc97bc3ff463; rkv=1.0; 3AB9D23F7A4B3C9B=AYPPGZRSRI2LQYVQZ3NIJPTSO2YKRJC244W6SAZG7G6MJMG2J7VMGS3HL4RIU2HBQZNWBVD5YXROM6PLXU44BZGEZ4"}
#新建五个列表
commentList = []
teaSkuList = []
userIDList = []
userNameList = []
timeList = []
teaInfo = pd.ExcelWriter(r"D:\xiazai\bishe\评论信息.xlsx")
#定义一个新函数getInfo,传入参数comment_url。用于获取商品评论信息。
def getInfo(comment_url):
# 使用get()函数请求链接,并且带上headers
comment_res = requests.get(comment_url, headers=headers)
if comment_res != None:
comment_res.encoding = comment_res.apparent_encoding
# 使用.text属性将服务器相应内容转换为字符串形式,赋值给html
comment_html = comment_res.text
time.sleep(2)
comment_html = comment_html.lstrip("fetchJSON_comment98(")
comment_html = comment_html.rstrip(");")
json.dumps(comment_html)
if comment_html != None:
json_data = json.loads(comment_html)
print(json_data)
data = json_data["comments"]
for c in data:
#取出字典c里"content"键对应的值(评论内容)
userID = str(c["id"])
userIDList.append(userID)
comment = c["content"]
commentList.append(comment)
orderTime = c["creationTime"]
timeList.append(orderTime)
teaSku = c["referenceId"]
teaSkuList.append(teaSku)
userName = c["nickname"]
userNameList.append(userName)
time.sleep(1)
for url in url_List:
res = requests.get(url, headers=headers)
html = res.text
soup = BeautifulSoup(html, "lxml")
# 使用find_all()查询soup中class="gl-item"的节点,赋值给content_all
content_all = soup.find_all(class_="gl-item")
# 使用for循环遍历content_all,获取单个茶叶商品的url
for content in content_all:
# 使用.attrs属性获取data-sku对应的属性值,并赋值给p_id
p_id = content.attrs["data-sku"]
comment_url = f"https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={p_id}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
getInfo(comment_url)
totalInfo = {"用户ID":userIDList, "用户名":userNameList, "商品编号":teaSkuList, "评论信息":commentList, "下单时间":timeList}
info = pd.DataFrame(totalInfo)
info.to_excel(excel_writer=teaInfo,sheet_name="评论信息")
teaInfo.save()
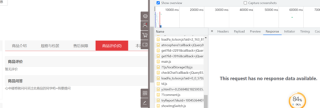
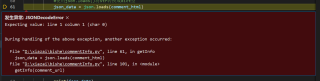
这个是报错信息
我复制该报错链接用网页打开就是一片空白