在做协同过滤有关的论文实验时,由于数据集比较稀疏,在利用
计算预测值时发现由于本身的评分矩阵比较稀疏,分母过小分子过大,预测值普遍偏小,在进行0-1分类的阈值设置上比较麻烦,想问一下有什么方法能对这种情况进行改进
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
https://blog.csdn.net/chaiqunxing51/article/details/50977195
报告相同问题?
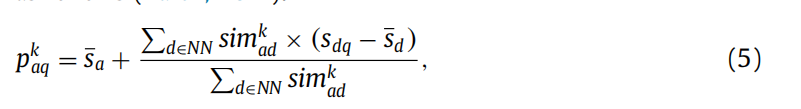

 分享
分享




