addr_dict=
{ '北京市':[['王*龙','北京市……'],
['庞*飞','北京市……'],
……
],
'江苏省':[['顾*锐','江苏省……'],
……
],
……
}
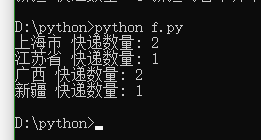
在“双11”结束后,对用户的快递订单进行统计
设计要求:
1.自己编写数据
2.提取每个快递订单的省份信息,并根据快递信息中的“省份”将订单存储到新字典addr_dict中。字典addr_dict的结构如上,其中“键(key)”为省份全名,“值(value)”为属于该省份的快递订单列表。
3.根据存储在字典对象addr_dict中的数据,统计并输出发往各省份的快递数量。
其他要求:
提供的快递信息中,特殊省份名称为两个字(实际省份全名多于3个字,如“新疆”实际应为“新疆维吾尔自治区”);正常省份或直辖市均为3个字(如浙江省、上海市)。
利用每个地址的前3个字符(省或直辖市),当做key,每次循环时,判断字典addr_dict(用于存放分拣结果)中有没有对应省份的key;若没有,则初始化新省份的键值对,加入一个快递信息;若有,直接调用对应省份的key,并追加新的快递信息。