- 我构建了一个DQN网络下五子棋,在进行AI博弈的时候发现AI的自我博弈虽然能使AI获得奖励但是在几千轮循环后网络还是无法做到有效的攻防(有目的的连接棋子,或者打断另一方五子相连)。
- 所以我引入了一个下五子棋的程序(通过评分差值下五子棋实现攻防),但是在引入程序后也不知道是程序太强还是里面的的随机性太大,导致在约7500次左右(训练次数是2w但是我看7500多次都没训练成功我就关掉了)的的训练中程序总能在5到16回合内KO掉DQN网络只也就导致了五子棋AI根本就得不到奖励,无法获得学习。
- 我的奖励是下棋:0分
- 获得胜利:1000分
- 范围超过或者平局-20分
- 请问大佬们,我要怎么做才能使这个网络实现有效的攻防和学习。
- 还有就是我用tensorboard的时候发现我的主网络和记忆库的的权重都未发生更新,请问有懂行的大佬知道吗
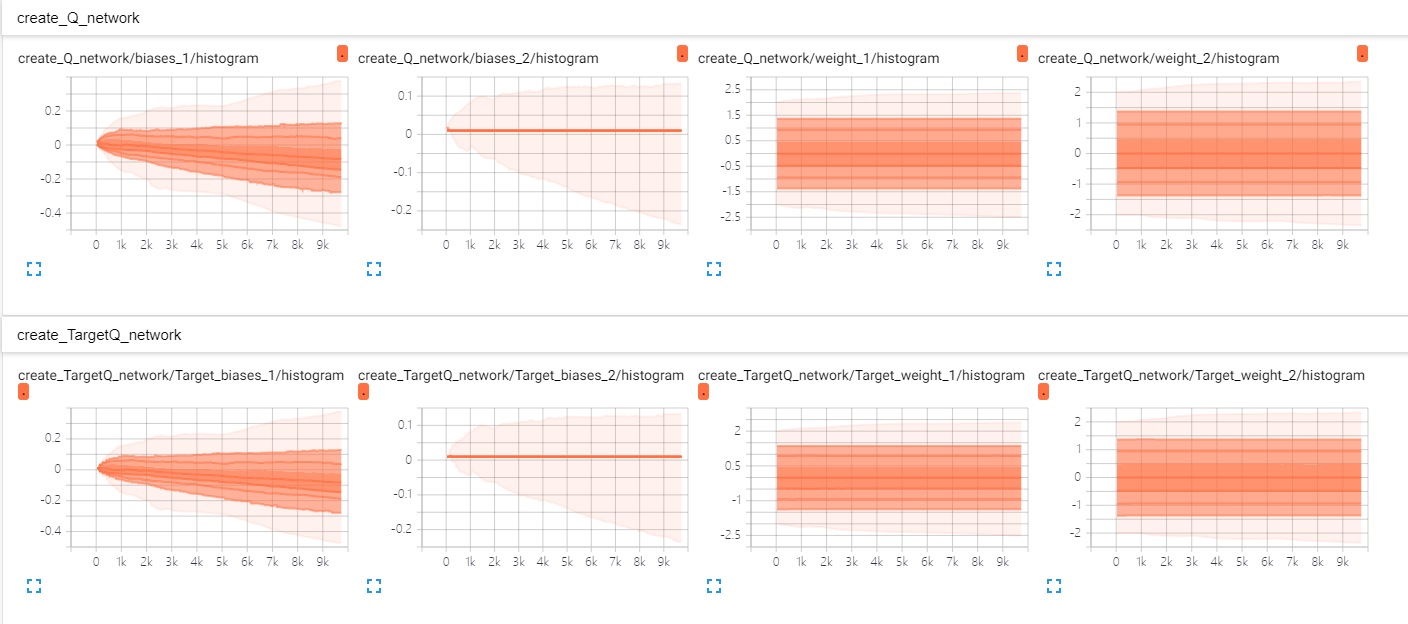

运用DQN模型,训练五子棋ai,加入五子棋程序后无法学习。

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


0条回答 默认 最新
- 2022-09-15 12:25回答 2 已采纳 你把gym换成0.25.2版本就行了。 pip install gym==0.25.2
- 2023-02-11 18:41回答 1 已采纳 以下答案引用自GPT-3大模型,请合理使用: ```想请问大神们,有没有比较好的资料或者指导方法,能够快速掌握深度强化学习的各种算法呢? 首先,你需要理解深度强化学习的基本概念。然后,你可以通过阅读相
- 2021-03-15 15:12回答 4 已采纳 应该是没有读取进来数据。在getstate函数里,for循环没有运行,所以state是None。也可能len(block)刚好等于1,而你又用len(block)-1,所以循环没有进行。我不知道你是不
- 2022-04-03 22:45人工智能_项目实践_强化学习_基于强化学习的五子棋
- 2021-03-18 10:05回答 10 已采纳 直接用pandas库来读就行 import pandas as pd data = pd.read_excel('文件名称',sheet_name='表单名称') stockData = list
- 2018-12-12 04:37回答 1 已采纳 已找到,使用图网络模型可以实现。
- 2017-06-05 08:39回答 1 已采纳 The problem here is that you are using attr where you shouldn't. You are treating the XMLEntry an
- 2023-08-10 10:58人工智能大作业基于python实现五子棋游戏源码(含棋子识别+搜索算法+ANN棋局评估+DQN的棋力提升).zip 1、该资源内项目代码都是经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关...
- 2022-11-09 15:31回答 2 已采纳 这是由于python版本过多导致的,打开终端第一行输入以下代码即可 !/user/bin/env python<你的版本ROS使用>
- 回答 2 已采纳 代码本身测试:这个代码在本地新建环境下使用是正常的错误解析: OSError: [Errno 9] Bad file descriptor Bad file descriptor 错误的文件描述符
- 2021-02-07 19:15回答 5 已采纳 还有你循环中 table.col_values(5,0,row_num) 每次获取0到row_num行的列表,获取数据重复了啊。 是不是应该改为 table.cell_value(row_nu
- 2021-03-14 14:24AI信仰者的博客 本文公开一个基于强化学习算法DQN的五子棋游戏自动下棋算法源码,并对思路进行讲解。 源码地址: python_强化学习算法DQN_玩五子棋游戏 一个基于CNN构成的DQN算法的8*8的五子棋游戏 1、Q-Learning介绍 Q-Learning的...
- 2022-10-27 10:42回答 1 已采纳 是的,把6改成4
- 2023-01-16 13:23甜辣uu的博客 对抗 DQN 网络 Adversarial-DQN”以及 MCTS 的结合 设计AI五子棋系统
- 2021-03-17 21:33此课程设计通过五子棋算法设计,加深对机器学习中强化学习概念的理解与应用。本次课程设计的任务如下: 1. 给出“自己与自己程序的对抗”的视频,给自己的棋盘加上自己特有的标签,作为你自己程序的论证(防抄袭),...
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 安卓adb backup备份应用数据失败
- ¥15 eclipse运行项目时遇到的问题
- ¥15 关于#c##的问题:最近需要用CAT工具Trados进行一些开发
- ¥15 南大pa1 小游戏没有界面,并且报了如下错误,尝试过换显卡驱动,但是好像不行
- ¥15 没有证书,nginx怎么反向代理到只能接受https的公网网站
- ¥50 成都蓉城足球俱乐部小程序抢票
- ¥15 yolov7训练自己的数据集
- ¥15 esp8266与51单片机连接问题(标签-单片机|关键词-串口)(相关搜索:51单片机|单片机|测试代码)
- ¥15 电力市场出清matlab yalmip kkt 双层优化问题
- ¥30 ros小车路径规划实现不了,如何解决?(操作系统-ubuntu)