大神,小白请教用正则或者beautifulsoup找到<p中的内容
不知道如何复制源码,这上面显示中文,标签都被省略了,抱歉,xie'xie'da'jia

爬虫爬取<p>和<p,title='...'>中所有<p>的标签?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答
 threenewbee 2019-07-28 21:38关注
threenewbee 2019-07-28 21:38关注没看到title
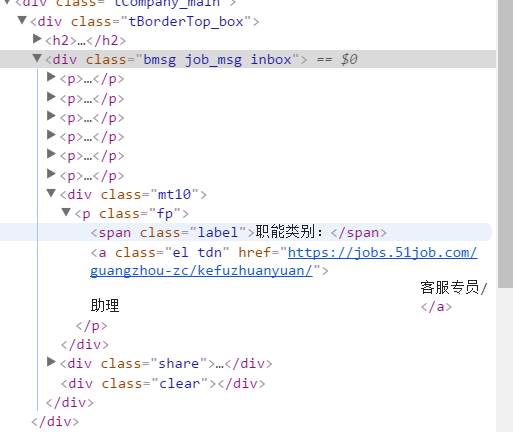
soup.select('p[class="fp"]')[1].text
这个可以得到"客服专员/助理"解决 无用评论 打赏举报 分享
- 2022-05-04 23:21回答 2 已采纳 import re s = "科技部发布国家重点研发计划<p>农业生物重要性状形成与环境适应性基础研究</p>等重点专项2022年度项目申报指南" res =re.find
- 2015-12-07 23:46回答 1 已采纳 You can get the children of an element using the children() method. If you can guarantee that the
- 2019-07-05 09:02回答 2 已采纳 找到问题所在了. 因为用了 sass 是不能用{}语法的.
- 2020-08-17 12:26阿智智的博客 问题描述 爬取新闻网页,HTML代码如下: <div id=ozoom style="ZOOM: 100%"> <founder-content> <P> 上图:1953年3月11日,我国第一座自动化的炼铁炉——...中,我在爬虫代码中匹配时写的仍然是大写
- 2022-10-12 12:43回答 4 已采纳 img src必须是图片的链接,https://www.baike.baidu.com/pic/大英帝国 你这个是网页链接,把src改成图片url
- 2022-09-21 11:27回答 4 已采纳 .*?点代表任意字符星表示前面的字符重复任意次数点星就表示任意长度的字符串问号表示非贪婪匹配,也就是匹配到第一个能跟后续字符匹配的字符串就结束-=-=-=那么好了,两个匹配,一个是item.*?tit
- 2021-09-17 21:21回答 2 已采纳 第一个i是dd的子元素,遍历的时候tag就包含i。i再找i,html结构中并没有i嵌入i的结构,所以无法找到。直接获取dd节点find_all下面的i节点就行有帮助麻烦点个采纳【本回答右上角】,谢谢~
- 2019-05-06 20:11weixin_33795833的博客 原博客地址: https://www.cnblogs.com/dengyg200891/p/6060010.html ... 2 #python 2.7 3 #XiaoDeng 4 #http://tieba.baidu.com/p/2460150866 5 #标签操作 6 7 8 from bs4 import ...
- 2016-11-28 22:43回答 2 已采纳 You might mean $_SERVER['PHP_SELF'] and not $_GET['PHP_SELF'] (though you could've named your para
- 2021-05-20 12:34回答 1 已采纳 // 构建多页面应用,页面的配置 pages: { index: { // page 的入口 entry: 'src/ind
- 2021-08-26 09:47回答 2 已采纳 url_get = requests.get(" http://music.163.com/song/media/outer/url?id%22
- 2020-11-20 08:28weixin_39667652的博客 从网络上获取网页内容以后,需要从这些网页中取出有用的信息,毕竟爬虫的职责就是获取有用的信息,而不仅仅是为了下来一个网页。获取网页中的信息,首先需要指导网页内容的组成格式是什么,没错网页是由 HTML「我们...
- 2021-11-27 11:36回答 3 已采纳 你爬虫应该是用requests发送http请求的吧,这个是无法从elements找到,你要在network的doc分析网页,你找不到的数据很大可能是ajax请求渲染前端的
- 2021-06-28 11:12数据分析与统计学之美的博客 所有的Python “爬虫“ 初学者,都应该看这篇文章!
- 2022-03-31 17:37hxgbieshuomeibanfa的博客 python爬虫基础(牛刀小试)
- 2022-09-24 14:52小白fighting.的博客 box-text > p') for content in contents: graph = content.string # 注意br标签 # 由于中间中间会在p标签中遇见一个 标签,而使用content.string时string属性只能匹配成对的标签,所以不进行处理会直接报错。...
- 2021-06-22 19:42秦少爷的琪琪的博客 div class="p-name p-name-type-2"><a target="_blank" title="Apple iPhone 6 (A1589) 16GB 金色 移动4G手机" href="//item.jd.com/1217493.html" onclick="searchlog(1,1217493,0,1,'','flagsClk=419495...
- 2019-12-05 09:39满是BUG的世界的博客 近来闲的无聊,天天逛CSDN看到python多火热多火热,就自己根据教程学习爬虫,参考了好几个博文,忘了地址是啥就不贴出来了 开发工具:PcCharm 开发环境:Python3.8 这次爬取的小说网站是:...
- 没有解决我的问题, 去提问


悬赏问题
- ¥50 有数据,怎么建立模型求影响全要素生产率的因素
- ¥50 有数据,怎么用matlab求全要素生产率
- ¥15 TI的insta-spin例程
- ¥15 完成下列问题完成下列问题
- ¥15 C#算法问题, 不知道怎么处理这个数据的转换
- ¥15 YoloV5 第三方库的版本对照问题
- ¥15 请完成下列相关问题!
- ¥15 drone 推送镜像时候 purge: true 推送完毕后没有删除对应的镜像,手动拷贝到服务器执行结果正确在样才能让指令自动执行成功删除对应镜像,如何解决?
- ¥15 求daily translation(DT)偏差订正方法的代码
- ¥15 js调用html页面需要隐藏某个按钮