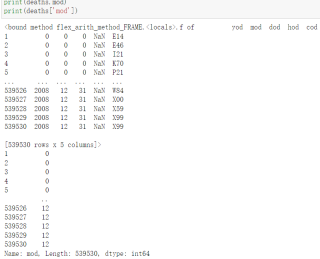
张金荣的Python程序设计与数据分析
为什么d2008_1真的出错了,取到了mod==0的数据。

需要用到一个文件"deaths.xlsx"
https://pan.baidu.com/s/13s2AMwqEoR1-Jse15b86gA
提取码c66t
以下是正确的代码d2008
import pandas as pd
import numpy as np
deaths=pd.read_excel('deaths.xlsx',index_col=0)
#d2008_1=deaths[(deaths.yod==2008)&(deaths.dod!=0) &(deaths.mod!=0)].dropna()
d2008=deaths[(deaths.yod==2008)&(deaths['dod'].ne(0))&(deaths['mod'].ne(0))].dropna()
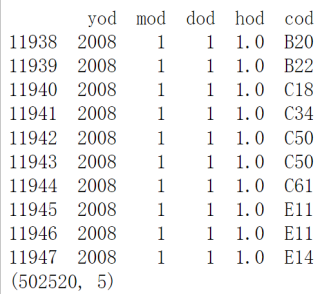
print(d2008.head(10))
print(d2008.shape)
运行结果为
以下是出问题的代码d2008_1
import pandas as pd
import numpy as np
deaths=pd.read_excel('deaths.xlsx',index_col=0)
d2008_1=deaths[(deaths.yod==2008)&(deaths.dod!=0) &(deaths.mod!=0)].dropna()
#d2008=deaths[(deaths.yod==2008)&(deaths['dod'].ne(0))&(deaths['mod'].ne(0))].dropna()
print(d2008_1.head(10))
print(d2008_1.shape)
运行结果为
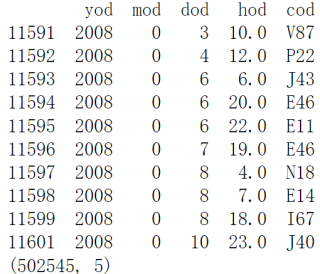
可以看到出错了,mod为0的数据没有被筛选出去。
关键点在于这两行代码的区别
d2008=deaths[(deaths.yod==2008)&(deaths['dod'].ne(0))&(deaths['mod'].ne(0))].dropna()
d2008_1=deaths[(deaths.yod==2008)&(deaths.dod!=0) &(deaths.mod!=0)].dropna()