import requests
from bs4 import BeautifulSoup
import pandas as pd
# 主函数
def main():
# 百度新冠疫情数据网址
url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner&city=%E5%8C%97%E4%BA%AC-%E5%8C%97%E4%BA%AC'
html = getUrlData(url)
total_data2 = getCitiData(html)
saveData(total_data2)
write_data(saveData, 'E:\py 文件\新冠抓取/BeiJing.csv')
# 获取网页数据
def getUrlData(url):
try:
# get请求,设置超时时间
r = requests.get(url, headers=headers, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
html = r.text
return html
except:
return '发生异常'
# 获取北京市每个区的疫情数据
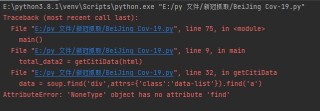
def getCitiData(html):
citi_name_data=[]
new_diagnosis_data=[]
existing_diagnosis_data=[]
cumulative_diagnosis_data=[]
cured_data=[]
new_cured_data=[]
dead_data=[]
new_dead_data=[]
asymptomatic_data=[]
new_asymptomatic_data=[]
total_data=[]
soup = BeautifulSoup(html,'html.parser')
data = soup.find('div',attrs={'class':'data-list'})
# 找到有唯一标识的属性的input标签
input1 = data.find('input',attrs={'id':'_209'})
# 找到input标签的的父标签
div = input1.parent
# 找到所有的li
li = div.find_all('li')
# 遍历li组成的列表
for i in range(1,len(li)):
# 获取区名称
citi_name = li[i].find('div',attrs={'class':'list-city-name'})
citi_name_data.append(citi_name.string+'区')
div = li[i].find_all('div',attrs={'class':'list-city-data'})
# 获取累计确诊人数
cumulative_diagnosis = div[0].string
cumulative_diagnosis_data.append(cumulative_diagnosis)
# 获取新增确诊人数
new_diagnosis = div[1].string
new_diagnosis_data.append(new_diagnosis)
#获取现有确诊人数
existing_diagnosis = div[2].string
existing_diagnosis_data.append(existing_diagnosis)
# 获取累计治愈人数
cured = div[3].string
cured_data.append(cured)
#获取新增治愈人数
new_cured = div[4].string
new_cured_data.append( new_cured)
# 获取累计死亡人数
dead = div[5].string
dead_data.append(dead)
# 获取新增死亡人数
new_dead = div[6].string
new_dead_data.append(new_dead)
#获取累计无症状人数
asymptomatic =div[7].string
asymptomatic_data.append(asymptomatic)
#获取新增无症状人数
new_asymptomatic = div[8].string
new_asymptomatic_data.append(new_asymptomatic)
total_data.append(citi_name_data)
total_data.append(cumulative_diagnosis_data)
total_data.append(new_diagnosis_data)
total_data.append(existing_diagnosis_data)
total_data.append(cured_data)
total_data.append(new_cured_data)
total_data.append(dead_data)
total_data.append(new_dead_data)
total_data.append(asymptomatic_data)
total_data.append(new_asymptomatic_data)
return total_data
# 保存数据
def saveData(total_data2):
df2 = data(total_data2)
# 将爬取的数据保存为csv文件
df2.to_csv("北京市各区的新冠肺炎疫情数据.csv",encoding='utf-8')
def data(total_data):
df = pd.DataFrame({'名称':total_data[0],'累计确诊':total_data[1],'新增确诊':total_data[2],'现有确诊':total_data[3],'累计治愈':total_data[4],
'新增治愈':total_data[5],'累计死亡':total_data[6],'新增死亡':total_data[7],'累计无症状':total_data[8],'新增无症状':total_data[9]})
# 将名称列设置为索引列
df = df.set_index('名称')
return df
# 程序入口
if __name__== "__main__":
main()
问题显示