折腾了老半天,还是不行,zookeeper已经跑起来了,就是kafka跑不起来,百度了很久,很多人说的CLASSPATH加引号的方法,我看了我的文件,直接就是加引号的。就真的不知道是什么问题了。
然后Java环境变量也没有放在有空格或者中文的路径下。
求大神指点迷津。
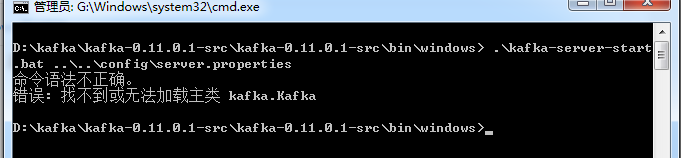
报错一直是:命令语法不正确.
错误:找不到或无法加载主类kafka.Kafka
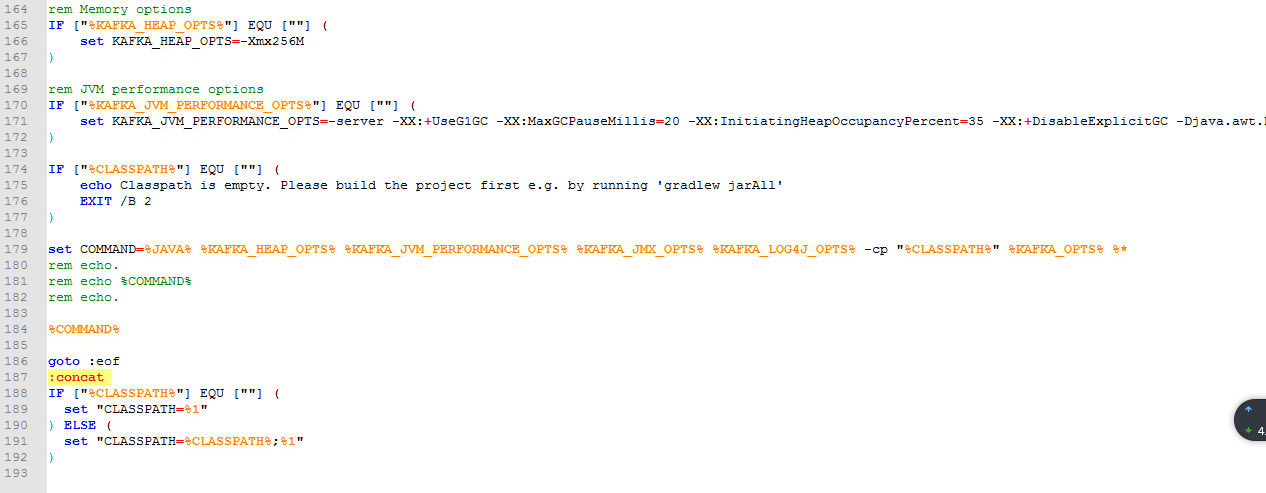

折腾了老半天,还是不行,zookeeper已经跑起来了,就是kafka跑不起来,百度了很久,很多人说的CLASSPATH加引号的方法,我看了我的文件,直接就是加引号的。就真的不知道是什么问题了。
然后Java环境变量也没有放在有空格或者中文的路径下。
求大神指点迷津。
报错一直是:命令语法不正确.
错误:找不到或无法加载主类kafka.Kafka
 分享
分享


