
我是跟这网上视频写的
import scrapy
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['www.qiushibaike.com/']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
print('='*10)
print(response)
print('*'*10)
出现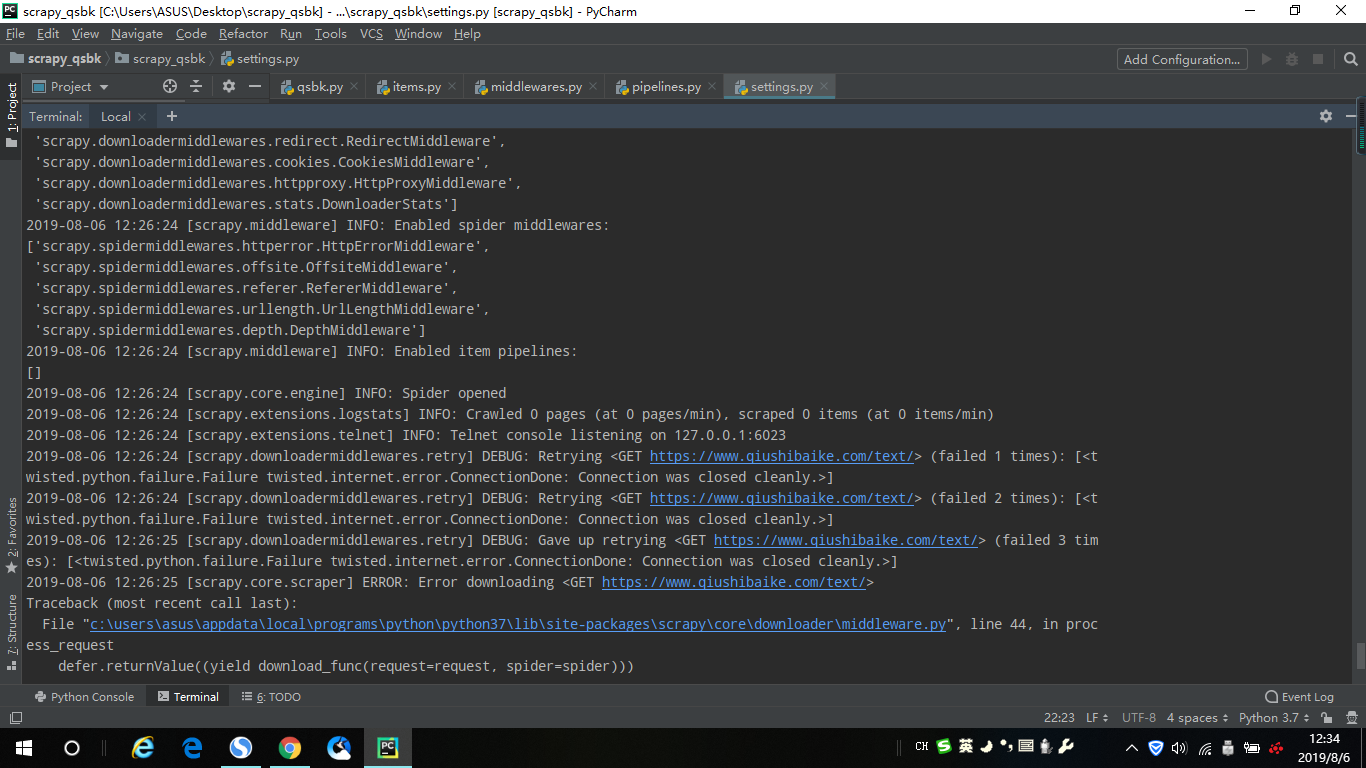
请求头改了还是不行,用requests库爬取又可以




