删除df中“mean”列数据小于1的行,怎么做筛选小于1的数值和行的链接
df表格样式
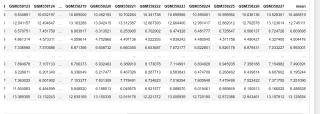

删除df中“mean”列数据小于1的行,怎么做筛选小于1的数值和行的链接
df表格样式
 分享
分享
 关注
关注可以用where()文件进行筛选:
newData = df.where(cond = (df['mean']>=1)).dropna()
还可以多条件筛选:
newData = df.where(cond = (df['mean']>=1) & (df['mean']<10) ).dropna()
newData = df.where(cond = (df['mean']>=1) | (df['mean']<0) ).dropna()
分享 系统已结题
5月30日
系统已结题
5月30日 已采纳回答
5月22日
创建了问题
5月14日
已采纳回答
5月22日
创建了问题
5月14日


