

问题遇到的现象和发生背景
根据关键字从多个txt中提取所在行数据,去除重复项并生成新的txt文件
问题相关代码,请勿粘贴截图
import os
path = "D:\Jupyter\银联数据\测试数据"# 文件夹目录
files = os.listdir(path) # 得到文件夹下的所有文件名称
for file in files: # 遍历文件
f = open(path+"\"+file).read() # 将打开的文件内容保存到变量f
log = open(path+"\"+'合成.txt', 'a+') # 以追加模式打开文件
log.write(f) # 写入文件
#print('已经合并:' + file)
#从合并文件中根据关键字提取数据
h = open('D:\Jupyter\银联数据\测试数据\合成.txt','r')
lines = h.readlines()
for lines in lines:
if "总计" in lines:
print(lines)
运行结果及报错内容
到这一步已经提取出了想要的数据,但是无法生成txt文件
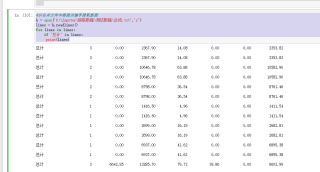
我的解答思路和尝试过的方法
尝试用了write函数,但是最终txt文件中只有最后一行数据
我想要达到的结果
所有在jupyter print出来的数据用txt输出








