
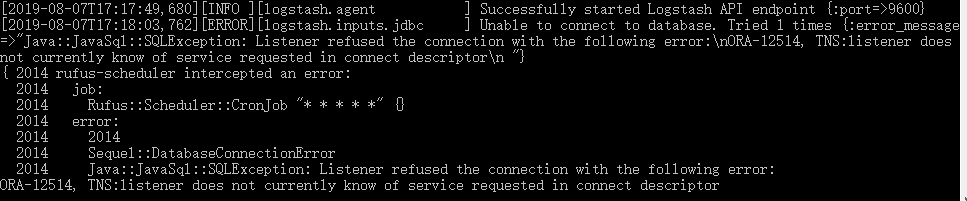
代码如下:
input {
jdbc {
jdbc_connection_string => "jdbc:oracle:thin:@//x.x.x.x:1521/ORCL213"
jdbc_user => "xxxxx"
jdbc_password => "xxxxx"
jdbc_driver_library => "D:\ES\elasticsearch-6.8.1\lib\ojdbc6.jar"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_paging_enabled => "true"
jdbc_page_size => "5"
statement => "select * from patient_recipes"
schedule => "* * * * *"
}
}





