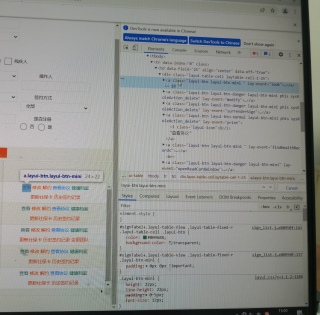
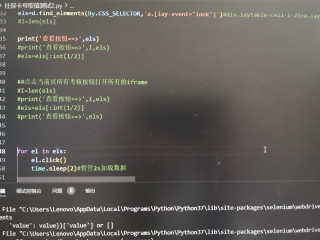
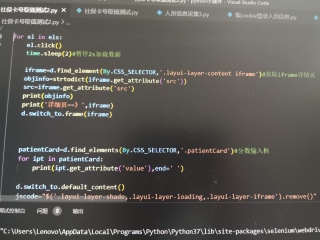
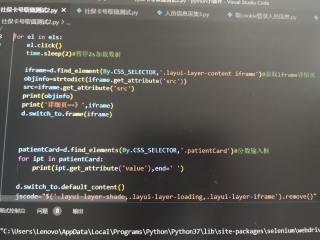
用BY.CSS_SELECTOR怎么让它连续点击查看,并且展开页面读取数据

用BY.CSS_SELECTOR怎么让它连续点击查看,并且展开页面读取数据
 分享
分享
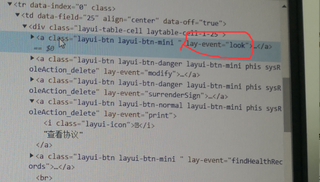
可以通过a[lay-event=look]这个样式来定位查看链接
分享 系统已结题
5月25日
系统已结题
5月25日 已采纳回答
5月17日
修改了问题
5月17日
创建了问题
5月17日
已采纳回答
5月17日
修改了问题
5月17日
创建了问题
5月17日

